
DeepSeek V4 Targets the AI Memory Shortage With Lower KV Cache Demands, But Performance Tradeoffs Remain a Key Question

DeepSeek is aiming directly at one of the biggest bottlenecks in modern AI infrastructure: memory. With its latest V4 model, the Chinese AI lab claims it has significantly reduced both compute and memory requirements during long context inference, potentially lowering the pressure on GPUs, HBM supply, and large scale AI deployment costs.
According to DeepSeek V4 release details reported by AI and technology outlets, DeepSeek V4 Pro can operate at a 1 million token context window while using only 27% of the single token inference FLOPs and just 10% of the key value cache compared with DeepSeek V3.2. The Flash variant is reportedly even more aggressive, using around 10% of the FLOPs and 7% of the KV cache compared with V3.2, although with weaker performance in more complex tasks. Reuters also reported that DeepSeek V4 is available in Pro and Flash variants, with V4 adapted for Huawei Ascend AI chips as China continues building a more independent AI hardware ecosystem.
The key technical story is the KV cache. In large language model inference, the compute process is often divided into 2 major phases: prefill and decode. During prefill, the model processes the input prompt or conversation history. During decode, the model generates new tokens while referencing the previously processed context. To do this efficiently, the model stores attention information in the KV cache. As context windows grow larger, that KV cache can become one of the biggest memory consumers in the entire inference pipeline.
That is why DeepSeek’s claim matters. A 1 million token context window is extremely demanding, and lowering KV cache requirements to 10% of the previous model could allow AI operators to serve longer contexts with less memory, support more concurrent requests on the same hardware, or reduce the amount of expensive HBM needed per deployment. Research around long context inference has already shown that KV cache activations can become a dominant memory bottleneck as context length increases, making compression and cache management central to scaling large models.
The broader hardware impact could be meaningful. The AI industry is currently under severe memory pressure, with demand for HBM, advanced DRAM, and accelerator memory capacity pushing the supply chain into a new supercycle. That demand does not stay isolated inside data centers. It can ripple into consumer DRAM, SSD pricing, and broader PC component availability. If software level improvements like DeepSeek V4’s cache reduction can extract more inference output per gigabyte of memory, the pressure on memory supply could eventually ease.
However, the tradeoff is performance consistency and output quality. Lowering memory usage this aggressively usually requires compression, approximation, selective attention, or architectural compromises. These techniques can work extremely well in many scenarios, but they can also introduce failure cases where the model misses small but important details hidden inside a long context. This is often described as a “needle in a haystack” problem, where the model technically supports a massive context window but may fail to retrieve or use a precise detail buried deep inside it.
That is the part of DeepSeek V4 that needs independent testing. A lower KV cache footprint is impressive, but the practical question is whether the model can maintain accuracy, reasoning quality, retrieval reliability, and instruction following across long prompts. For enterprise users, legal workflows, coding agents, research systems, and multi document analysis, missing one critical detail can be more damaging than simply running slower.
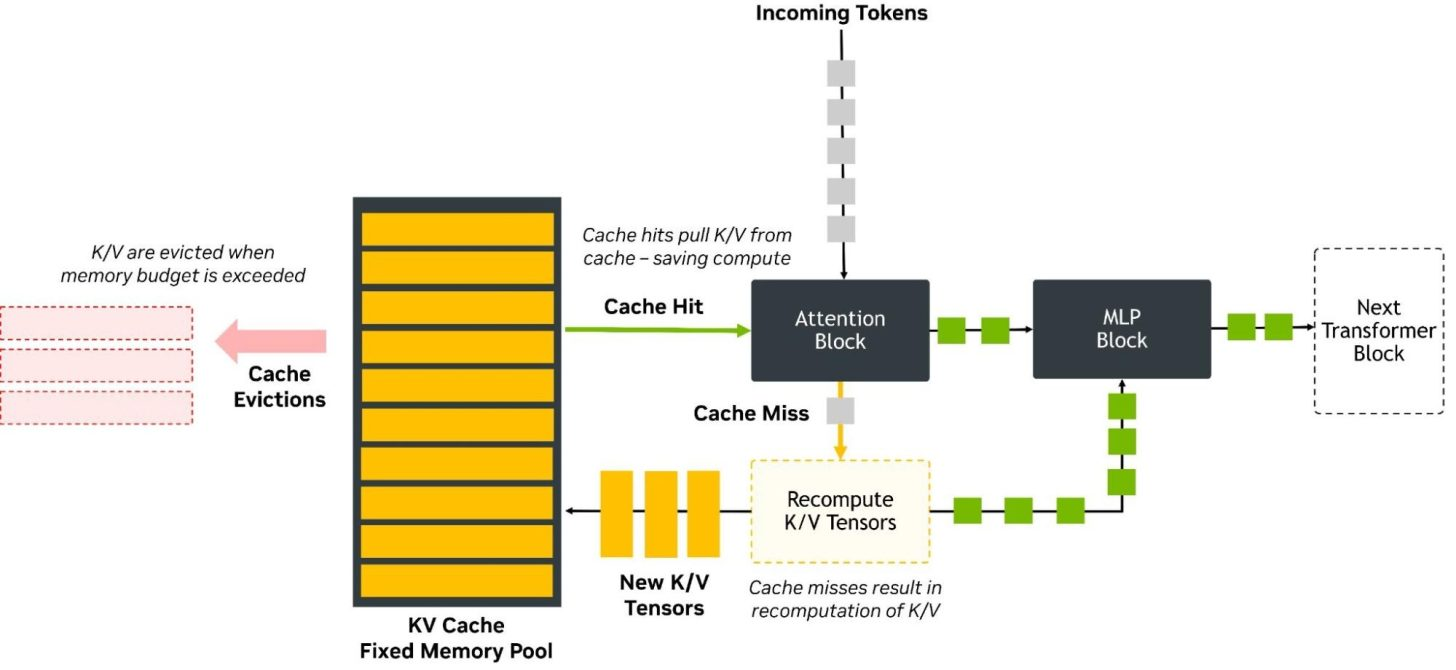
DeepSeek’s efficiency gains are reportedly built around its memory efficient attention architecture. Earlier DeepSeek models introduced Multi Head Latent Attention, or MLA, which compresses key and value representations into a lower dimensional latent form rather than storing the full tensors for every token. This compress then expand design reduces the KV cache memory burden while still allowing the model to reconstruct useful attention information during computation. Newer discussion around V4 also points to more aggressive compressed attention approaches designed specifically for million token context workloads.
This approach is part of a wider industry direction. Model builders are no longer only scaling parameters and training data. They are also redesigning inference architecture to reduce memory cost, lower power consumption, improve throughput, and make long context deployment economically viable. Techniques such as KV cache quantization, compressed attention, CXL backed memory expansion, and processing near memory are all being explored as the industry tries to make long context AI practical at scale.
For DeepSeek, the timing is important. The company is also adapting V4 for Huawei Ascend AI chips, which gives the model extra significance inside China’s AI ecosystem. With export restrictions limiting access to the most advanced NVIDIA hardware, Chinese AI companies are under pressure to build models that run efficiently on domestic accelerators. A model that uses less memory and fewer FLOPs could be strategically valuable if hardware availability remains constrained.
Still, lower memory usage does not automatically mean better real world performance. The Flash version may offer stronger cost efficiency, but Reuters reported that it can show weaker world knowledge and lower performance on more demanding agent based tasks compared with the Pro model. That distinction matters because the AI market is increasingly moving toward agentic workloads, where models need to plan, remember, retrieve, call tools, and maintain task continuity across long sessions.
The best way to view DeepSeek V4 is as a major efficiency play rather than a guaranteed quality breakthrough. If its claims hold up under third party testing, the model could help reduce the memory burden of long context inference and make large scale AI deployment more affordable. But if aggressive compression causes retrieval failures or weaker reasoning under complex workloads, then the savings may come with a cost that some users cannot accept.
For the AI hardware market, this is still an important development. The industry cannot solve the memory crisis through HBM production alone. Demand is growing too quickly, and AI models continue to push context size, agent memory, and inference concurrency higher. Software efficiency, model architecture, cache compression, and smarter memory management will all be required to keep the market sustainable.
DeepSeek V4 may not eliminate the AI memory shortage, but it points toward the kind of optimization the industry needs. The next challenge is proving that lower memory usage does not come at the expense of the precision, reliability, and long context recall that advanced AI users increasingly depend on.
Will DeepSeek V4’s aggressive memory savings help ease the AI hardware crunch, or will the performance tradeoffs limit its real world impact?