
Sandisk Explores Stacking AI Compute Directly Above NAND as HBM Limits Tighten

Sandisk is exploring a more aggressive approach to the AI memory bottleneck, with a patented architecture that places a GPU or AI accelerator directly above a high capacity NAND memory tile while retaining conventional HBM stacks on the same interposer. The design could eventually create a new memory hierarchy where HBM handles the most urgent data while integrated NAND keeps much larger models and data sets physically closer to the processor.
The idea is described in United States patent 12,430,274 B2, titled Processing Core Including Integrated High Capacity High Bandwidth Storage Memory. The patent was filed on November 27, 2023 and granted on September 30, 2025 to Sandisk Technologies.
Its proposed package combines a multicore processor with a CBA memory tile. CBA means CMOS Bonded to Array, a structure that joins a large NAND array with a separate CMOS logic layer. The processor, which could be a GPU, AI accelerator, TPU, or another specialized computing device, would sit directly above the NAND tile. The combined structure would then be attached to an interposer surrounded by HBM stacks.
This is different from simply placing a conventional SSD close to a GPU. The patent describes a wide physical interface between the compute die and the NAND tile, reducing the distance that information must travel and allowing more parallel connections than a traditional storage bus. In theory, the design could lower data movement costs while giving an accelerator access to far more local capacity.
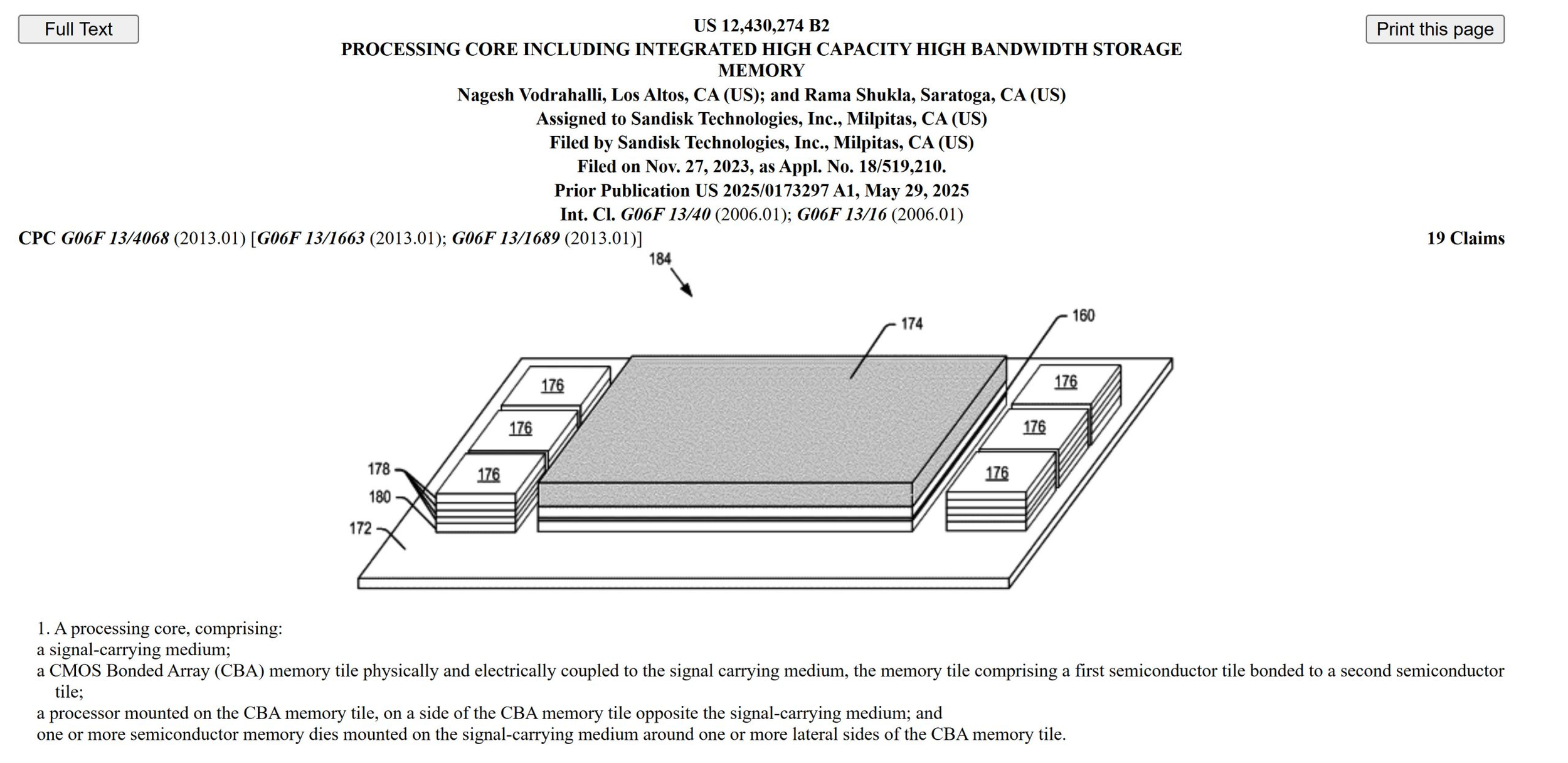
HBM would still play a critical role. Its DRAM based design offers much lower latency than NAND and is better suited to active calculations, frequently accessed data, and temporary working memory. The integrated NAND tile would instead hold larger volumes of model weights, vector data, inference context, and other information that does not need to move at full HBM latency.
That division of work could become increasingly important as AI models outgrow the memory capacity available around individual accelerators. HBM bandwidth continues to improve, but production remains expensive and technically demanding. Stacking more DRAM dies also creates challenges involving yield, packaging, thermals, power consumption, and supply availability.
NAND offers much greater capacity at a lower cost, but its latency and endurance characteristics make it unsuitable as a direct replacement for DRAM across every workload. Sandisk’s concept attempts to use both technologies for the jobs they perform best rather than forcing one memory type to handle the entire system.
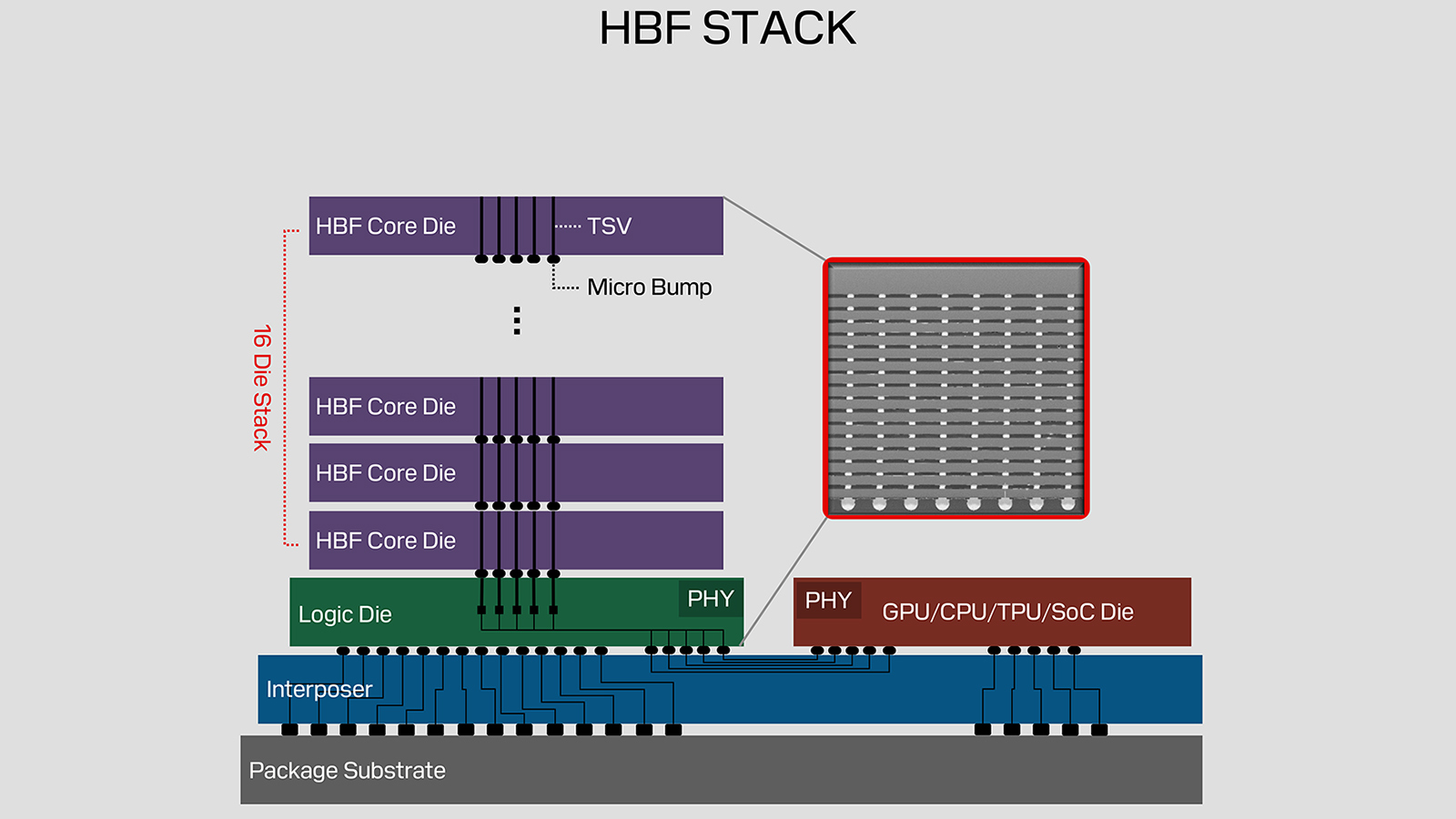
The patent is closely related to Sandisk’s wider investment in High Bandwidth Flash, although the 2 concepts should not be treated as the same commercial product. HBF uses vertically stacked NAND dies, through silicon vias, dedicated logic, and CBA wafer bonding to create extreme internal parallelism.
Sandisk says its current HBF design can closely approach HBM bandwidth while providing 8 to 16 times more capacity at a similar cost. Its first public configuration targets 512 GB in a 16 die stack, while multiple stacks around an accelerator could produce systems with several terabytes of attached flash memory.
The company’s internal simulation using the 405 billion parameter Llama 3.1 model showed HBF performing within 2.2% of a theoretical system with unlimited HBM when reading pretrained 8 bit weights. That result is based on modeling rather than final shipping hardware, but it illustrates Sandisk’s argument that bandwidth can sometimes matter more than individual access latency during read intensive AI inference.
Sandisk plans to deliver its first HBF samples during the second half of 2026, with initial AI inference devices using the technology expected to enter sampling in early 2027. The company is also working with SK hynix to standardize HBF through a dedicated Open Compute Project workstream.
That standardization effort is important because memory technologies only achieve broad adoption when accelerator designers, packaging companies, server makers, software developers, and cloud providers agree on interfaces and operating requirements. A proprietary Sandisk solution could find limited customers, but an industry standard supported by SK hynix would have a much stronger chance of becoming a recognized AI memory layer.
The patent takes the concept further by placing NAND directly underneath compute rather than positioning separate HBF stacks beside the processor. This could offer a much wider interface and shorter physical path, but it would also create significant manufacturing challenges.
Stacking a high power GPU directly above NAND could make heat removal extremely difficult. NAND reliability and data retention are sensitive to temperature, while AI processors already require complex cooling systems. The combined package would also need to manage different manufacturing processes, die sizes, thermal expansion behavior, yields, and replacement risks.
Cost presents another concern. HBF is partly attractive because NAND can deliver more capacity for less money than HBM. A complex 3D package containing an advanced accelerator, CBA NAND tile, interposer, HBM stacks, and wide vertical connections could reduce that advantage if manufacturing yields are low.
Software would also need to understand the new memory hierarchy. Operating systems, AI frameworks, compilers, and model runtimes would have to decide which information belongs in HBM, integrated NAND, system memory, or remote storage. Poor data placement could erase the performance and power benefits of the hardware.
The wider market pressure explains why Sandisk is protecting concepts this ambitious. AI demand is pushing memory suppliers toward HBM, advanced packaging, enterprise NAND, and other higher value products, while Silicon Motion warned that DRAM and SSD shortages could continue into 2028.
Sandisk’s patent is best viewed as a strategic map rather than a product announcement. The company is currently advancing the simpler HBF approach, where NAND stacks sit beside an accelerator in a layout inspired by HBM. The patented processor above NAND structure represents a more ambitious option that Sandisk could pursue if packaging, cooling, and software improve enough to make it practical.
The underlying direction is clear. Future AI systems may no longer rely on a single category of memory. HBM, NAND, DRAM, CXL memory, and remote storage could become parts of a coordinated hierarchy, with each layer balancing speed, capacity, power, persistence, and cost.
Could high bandwidth NAND become the missing memory layer for AI inference, or will its latency and thermal challenges prevent it from moving close to the processor?