
AMD Steps Into 2nm With EPYC Venice Zen 6 And Instinct MI455X, Targeting Helios AI Rack With Liquid Cooling, HBM4, And Multi Exaflop Scale

AMD has showcased its first 2nm era data center silicon for the Helios AI Rack, pairing next generation EPYC Venice processors built on Zen 6 with Instinct MI455X accelerators in a rack scale design that AMD positions for next wave training and inference density. AMD confirms Helios is powered by Instinct MI455X and EPYC Venice, and frames the platform as a full stack push that includes Pensando networking and data processing to keep the AI pipeline fed at scale.
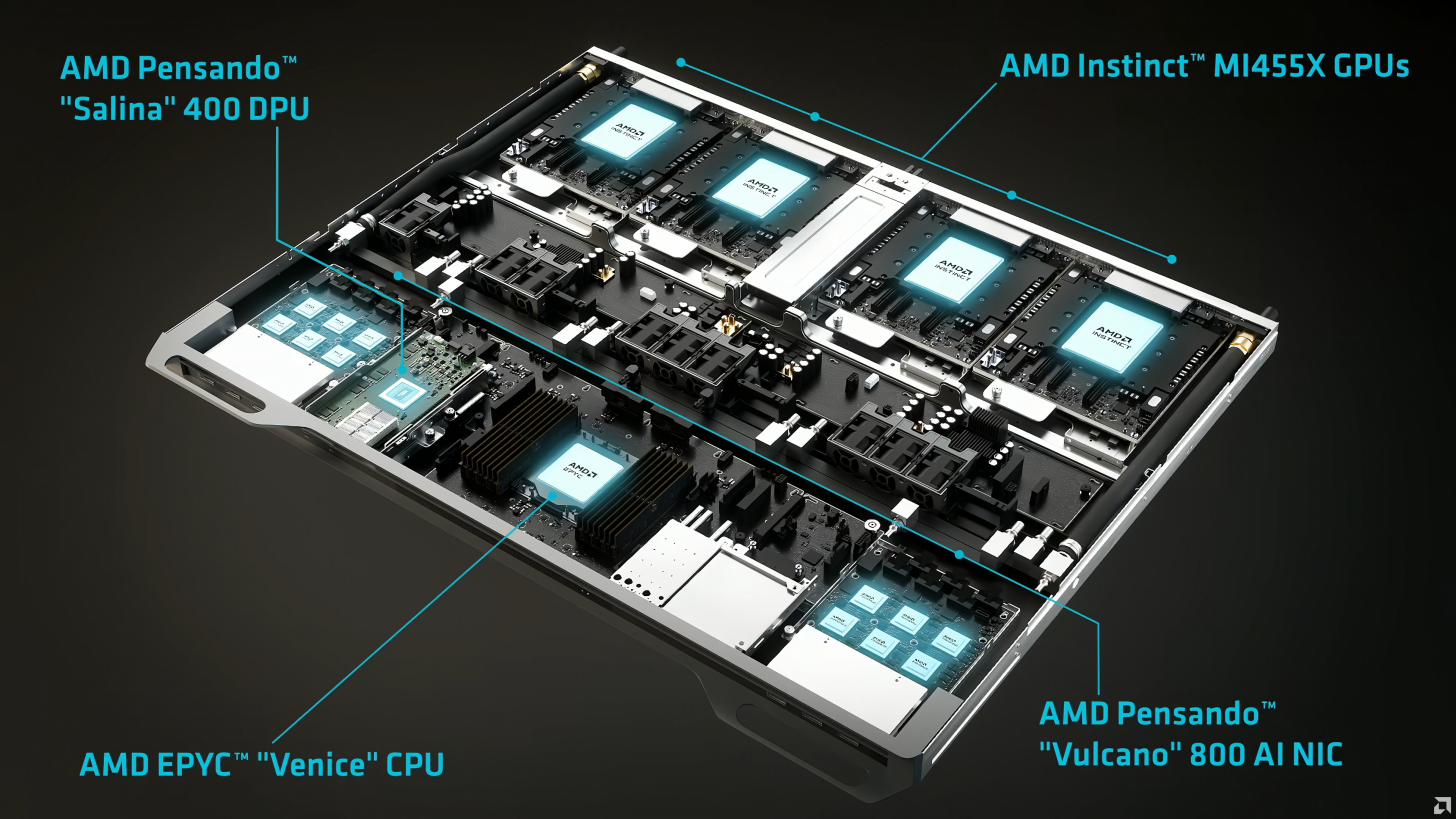

At the system level, Helios is described as a fully liquid cooled rack that combines 4 Instinct MI455X GPUs with 1 EPYC Venice CPU, plus Pensando Salina 400 DPU and Vulcano 800 AI NIC for interconnect and scale out networking. AMD is selling a clear enterprise value proposition here: higher performance per rack, higher memory capacity, and better bandwidth economics without treating networking as an afterthought.
AMD also shared top line rack scale targets that are designed to land with hyperscalers and neoclouds. The Helios rack is presented as scaling to 2.9 exaflops of AI compute, 31TB of HBM4 memory, and 43TB per second of scale out bandwidth, alongside platform level totals that reach up to 4600 CPU cores and 18000 GPU cores depending on rack configuration. These are density first numbers, and they underline AMD’s intent to compete on full platform throughput, not just single chip peak.

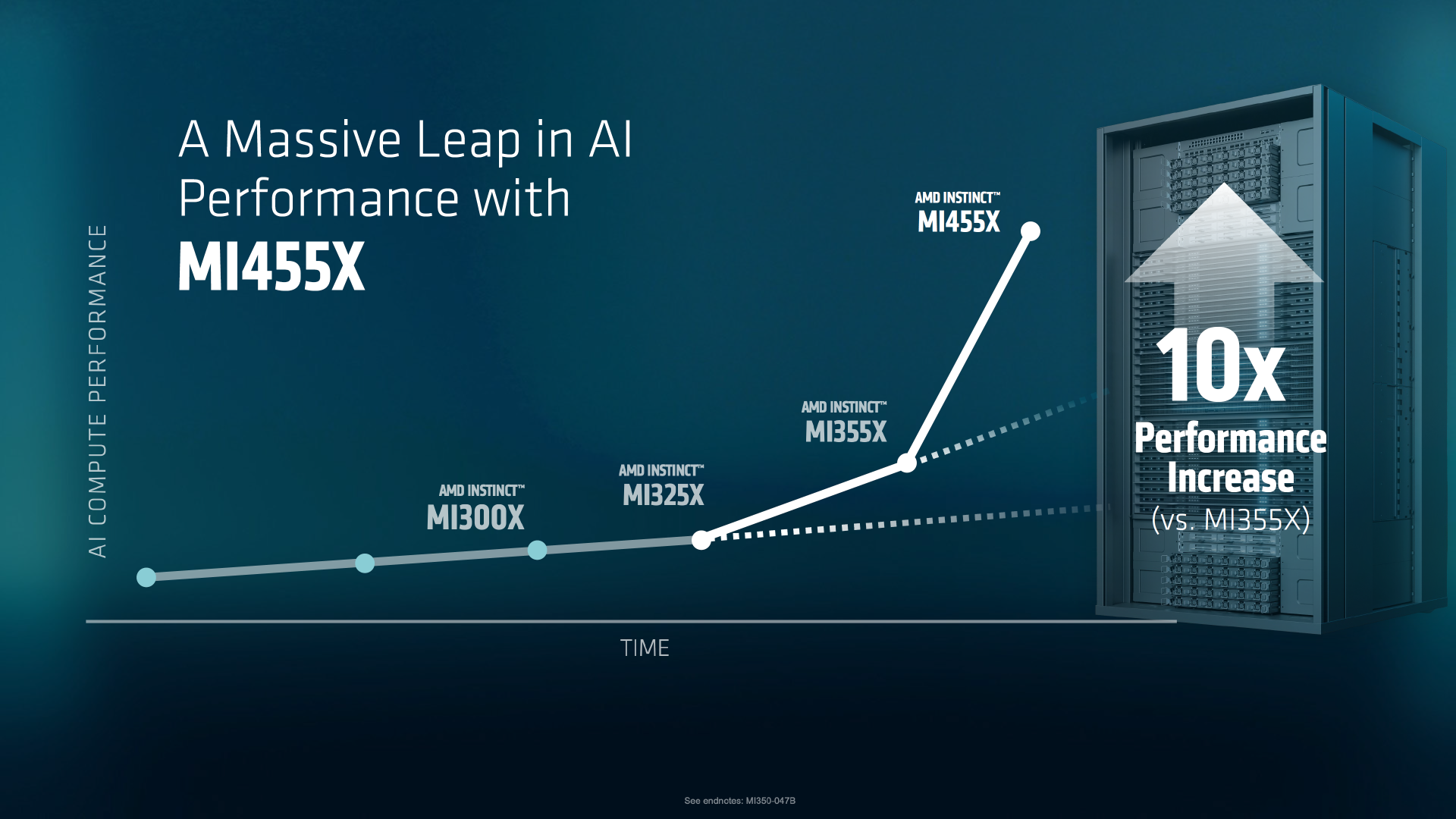
On the GPU side, AMD is positioning MI455X as a major packaging and memory leap. AMD describes the accelerator as using multiple large compute dies and a HBM4 heavy layout, and prior roadmap specs for the MI400 family point to 432GB of HBM4 per GPU with up to 19.6TB per second memory bandwidth per chip, plus FP4 and FP8 performance targets aimed directly at modern transformer workloads and mixture of experts training. AMD also claims competitive parity on several scale up metrics while emphasizing advantages in scale out bandwidth and memory capacity versus the competition.

On the CPU side, EPYC Venice is being framed as a foundational upgrade for both traditional server consolidation and AI orchestration. AMD has discussed Venice scaling up to 256 cores using Zen 6C, alongside a performance and efficiency uplift of over 70% and a thread density increase over 30%, signaling a push to maximize throughput per socket while reducing total platform power for the same work done. This is exactly the kind of KPI that matters when AI racks are constrained by power delivery and cooling, not just silicon capability.



The broader strategic takeaway is that AMD is attempting to win with an open rack narrative and a complete data center portfolio, not a single hero chip. That includes Helios for hyperscale AI racks, enterprise focused multi GPU systems, and hybrid compute options that span CPU heavy and GPU heavy deployments. The commercial timeline AMD is communicating aligns around customer availability in 2H 2026, which sets the stage for 2026 becoming a transition year where early adopters ramp Helios while current generation accelerators continue to ship in parallel.


From a gamer and enthusiast lens, this is the same playbook we see in high end PC builds, only magnified to rack scale. More bandwidth, more memory, more cooling headroom, and a tighter integration story so the platform can stay in boost behavior longer and deliver steadier performance under real workloads. AMD is essentially building an AI super rig where the rack is the new chassis, liquid cooling is mandatory, and memory is the real end game.
Do you think AMD’s Helios strategy will resonate more with buyers who want open Ethernet style scale out, or will NVIDIA’s tighter proprietary stack still dominate data center purchasing decisions in 2026?