
NVIDIA To Dominate The AI Markets With Its Rubin Platform

NVIDIA has formally unveiled its next generation data center AI platform, Vera Rubin, positioning it as the company’s most ambitious full stack architecture yet and a major step beyond the current Blackwell era. The announcement landed during CES 2026, with NVIDIA stating the Rubin platform is already in full production, and that partner systems are planned to roll out in the 2nd half of 2026.

At a platform level, Rubin is not a single chip refresh. NVIDIA is framing Vera Rubin as a 6 component ecosystem designed to scale from individual systems into rack level and pod level deployments with a unified compute and networking fabric. The 6 chips NVIDIA highlighted are the Vera CPU, Rubin GPU, NVLink 6 switch, ConnectX 9 SuperNIC, BlueField 4 DPU, and Spectrum X 102.4T co packaged optics infrastructure, all intended to be deployed across DGX, HGX, and MGX class systems.

On the GPU side, NVIDIA is positioning Rubin as a dedicated AI engine with aggressive throughput targets. NVIDIA has cited up to 50 PFLOPs NVFP4 inference and 35 PFLOPs NVFP4 training per Rubin GPU, with a claimed uplift of up to 5x for inference and 3.5x for training versus Blackwell depending on configuration and workload. Rubin also introduces HBM4 in the platform messaging, with NVIDIA highlighting major bandwidth gains versus the prior generation.
For the CPU, Vera is a custom Arm design built around NVIDIA’s Olympus cores. NVIDIA specifies 88 Olympus cores and 176 threads, plus NVLink C2C coherent connectivity and large system memory capacity via LPDDR5x based SOCAMM modules, while claiming a 2x uplift in data processing and related throughput versus Grace. In practical terms, this is NVIDIA tightening the coupling between CPU side orchestration and GPU side execution so rack scale AI systems can spend more time doing useful work and less time waiting on data movement and coordination overhead.


NVLink 6 is a key pillar in how NVIDIA intends to scale Rubin. NVIDIA highlights 6th gen NVLink and a new switch fabric to drive higher scale up bandwidth per GPU and all to all connectivity at rack level, with a major emphasis on liquid cooling and reliability at extreme density. When you layer in the networking stack, ConnectX 9 and BlueField 4 are positioned to push 800G class capabilities, RDMA acceleration, security, and storage processing so the overall system can sustain utilization at massive scale rather than bottlenecking at the edge of the rack.

Security and resilience are also front and center. NVIDIA is explicitly calling out 3rd gen confidential computing and rack scale trusted execution capabilities, paired with a 2nd gen RAS engine concept focused on health checks and minimizing downtime. This matters because the economics of modern AI are increasingly defined by availability and predictable throughput, not just peak FLOPs.



At the rack level, NVIDIA is anchoring the story around the Vera Rubin NVL72 system, which is framed as a major uplift over Blackwell class racks. NVIDIA and early technical breakdowns cite large increases in NVFP4 inference throughput, training throughput, scale up bandwidth, and both HBM4 and LPDDR5x capacity, along with a push toward more modular rack integration. NVIDIA also describes new “context memory storage” for inference, designed to help serve large scale chatbot and agent workloads more efficiently by improving how context is stored and accessed during inference.
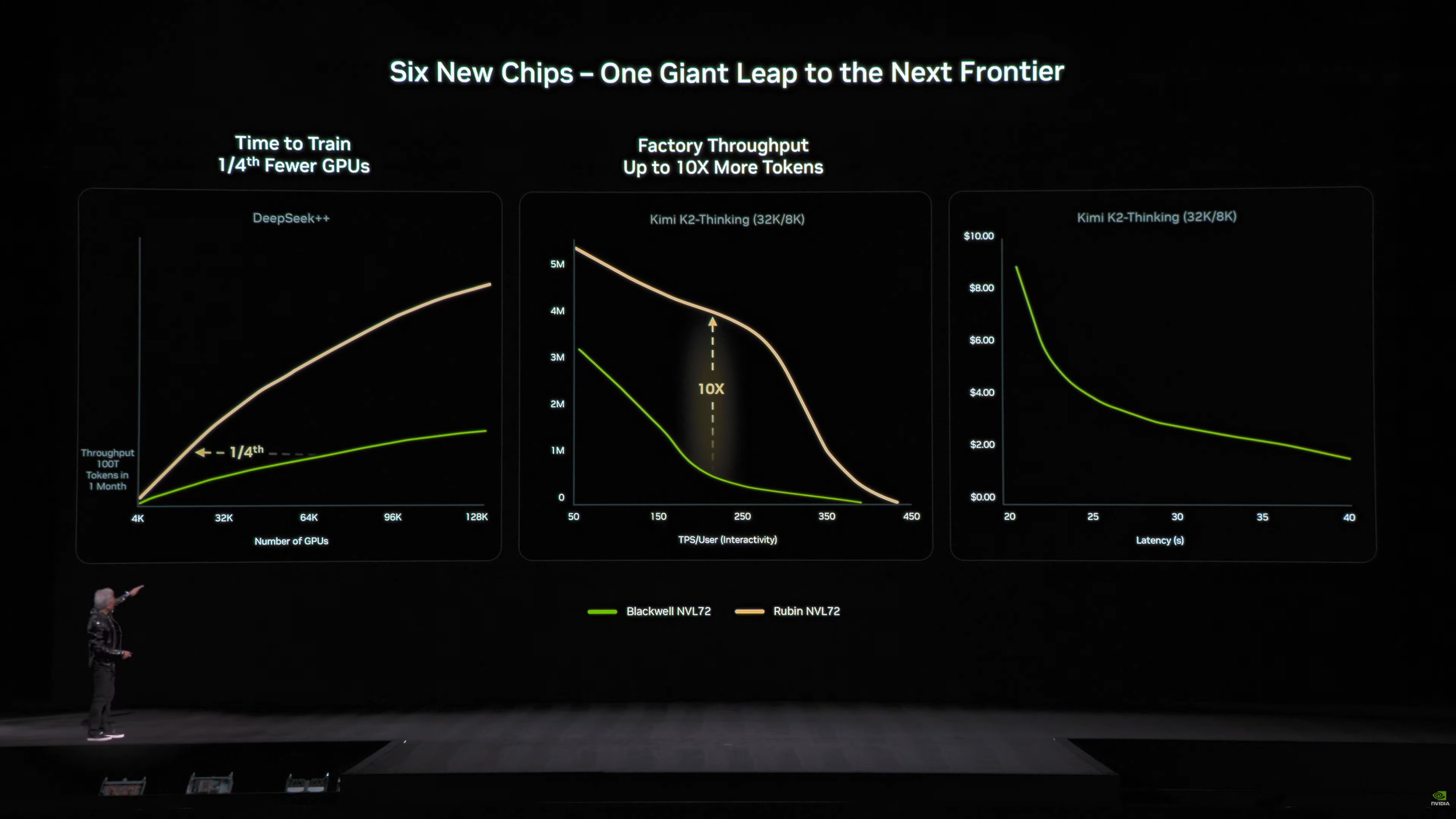
From a market lens, the message is clear. Rubin is NVIDIA doubling down on an integrated platform play where compute, interconnect, networking, optics, and software are treated as one product. NVIDIA is claiming improved token economics and fewer GPUs required for certain mixture of experts training scenarios compared to Blackwell, which is exactly the KPI enterprise AI teams are optimizing around heading into 2026 and beyond.
Do you think NVIDIA’s 6 chip full stack approach is the right long term play for AI infrastructure, or will hyperscalers push harder into custom silicon and open networking to break platform lock in?