
Micron Ships the World’s First 256GB SOCAMM2 Modules Targeted Toward the Agentic AI Frenzy

Micron is pushing the memory conversation deeper into the AI infrastructure spotlight with the launch of its newest SOCAMM2 modules, now scaling to a per module capacity of 256GB. In its latest announcement on the Micron investor site, the company says it is setting a new benchmark by moving beyond the previous 192GB ceiling and positioning SOCAMM2 as a purpose built answer to memory constraints that are increasingly defining modern AI deployments.

The strategic narrative here is clear. As AI systems move up the stack into the applications layer, the pressure on memory expands beyond raw throughput and into the world of responsiveness, latency, and long context handling. Micron is explicitly framing SOCAMM2 as a bottleneck reducer for AI workloads that rely heavily on context retention and retrieval, including scenarios tied to KV cache behavior and long context inference. In other words, the memory subsystem is no longer just a support component. It is becoming a primary performance lever for next generation inference pipelines.
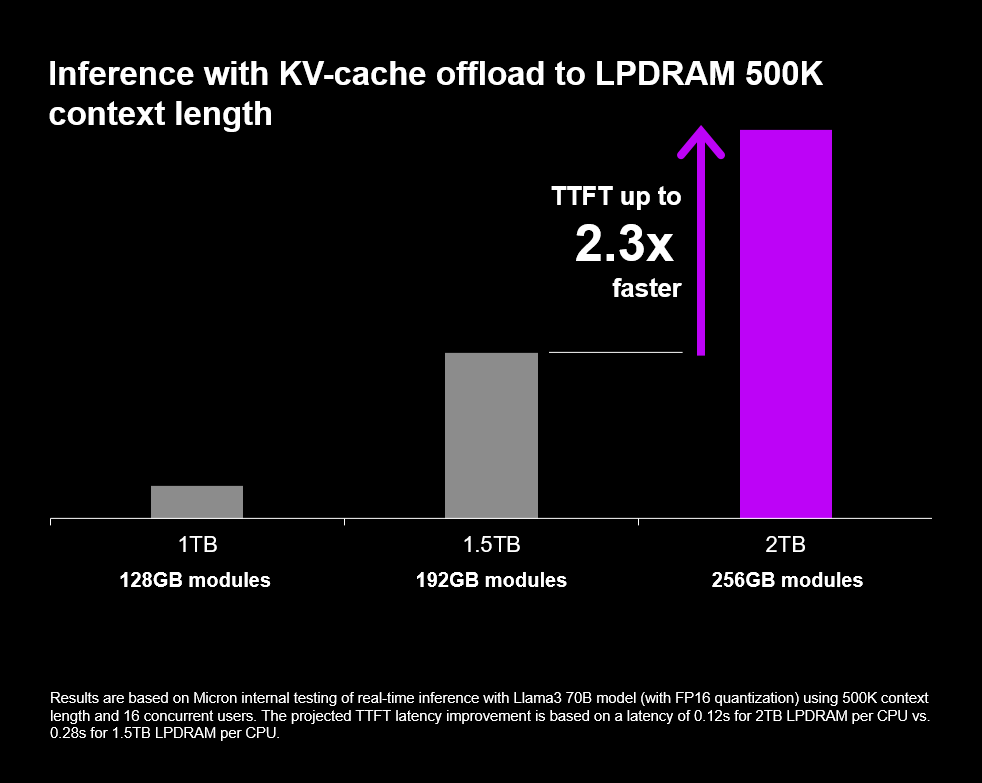
Micron also highlights a key technical step forward with this iteration, increasing the capacity of a single LPDRAM monolithic die to 32GB. With the 256GB SOCAMM2 configuration, Micron says an 8 channel CPU platform can reach up to 2TB of LPDRAM capacity, aiming to help AI servers process longer context windows more efficiently. The company further claims that with the new SOCAMM2 solution, TTFT improves by 2.3 times in long context inference, a metric that directly maps to perceived responsiveness in real world agentic style workloads where standalone CPU driven inference paths can matter.
NVIDIA’s involvement is also a major signal. Micron describes SOCAMM2 as a cooperative effort with NVIDIA, and includes a statement from Ian Finder, Head of Product, Data Center CPUs at NVIDIA, emphasizing that 256GB SOCAMM2 delivers high capacity and bandwidth using less power than traditional server memory, enabling the next generation of AI CPUs. The power efficiency angle is important because the industry is hitting a wall where performance scaling without power scaling is becoming the defining constraint across racks, clusters, and data center budgets.
From a market impact standpoint, SOCAMM2 is also positioned as a supply gravity product. High capacity AI focused memory solutions can meaningfully influence broader DRAM allocation strategy, and Micron itself notes that SOCAMM2 could consume a meaningful portion of DRAM supply, potentially tightening availability for more general purpose segments. If agentic AI demand continues to accelerate, SOCAMM2 becomes more than a spec sheet flex. It becomes a prioritization decision that can ripple across the wider ecosystem.
Micron says 256GB SOCAMM2 samples have already shipped to customers and that the solution will be showcased at GTC 2026, which strongly suggests the company is moving beyond concept messaging and into active platform adoption cycles.
Do you see SOCAMM2 as the next must have memory standard for AI servers, or do you think HBM will keep dominating while SOCAMM2 stays more niche for CPU centric inference platforms?