
Intel and SambaNova Push a New Inference Playbook as the Industry Moves Beyond GPU Only AI Infrastructure

Intel and SambaNova have announced a new heterogeneous inference architecture built around GPUs for prefill, Intel Xeon 6 processors as host and action CPUs, and SambaNova RDUs for decode, positioning the partnership as a direct response to the growing industry shift toward specialized inference stacks rather than GPU only deployments. The announcement came directly from Intel and SambaNova on April 8, 2026, and it reflects a broader change in AI infrastructure design as agentic workloads put more pressure on latency, orchestration, and token generation efficiency.
That strategic direction is not happening in isolation. At GTC 2026, NVIDIA highlighted disaggregated inference as a major part of its next generation platform strategy, and it formally introduced NVIDIA Groq 3 LPX for the Vera Rubin platform as a low latency inference accelerator for agentic systems. In other words, even NVIDIA is now signaling that future inference leadership will come from heterogeneous designs that split work across different types of compute rather than forcing every stage through the same accelerator.
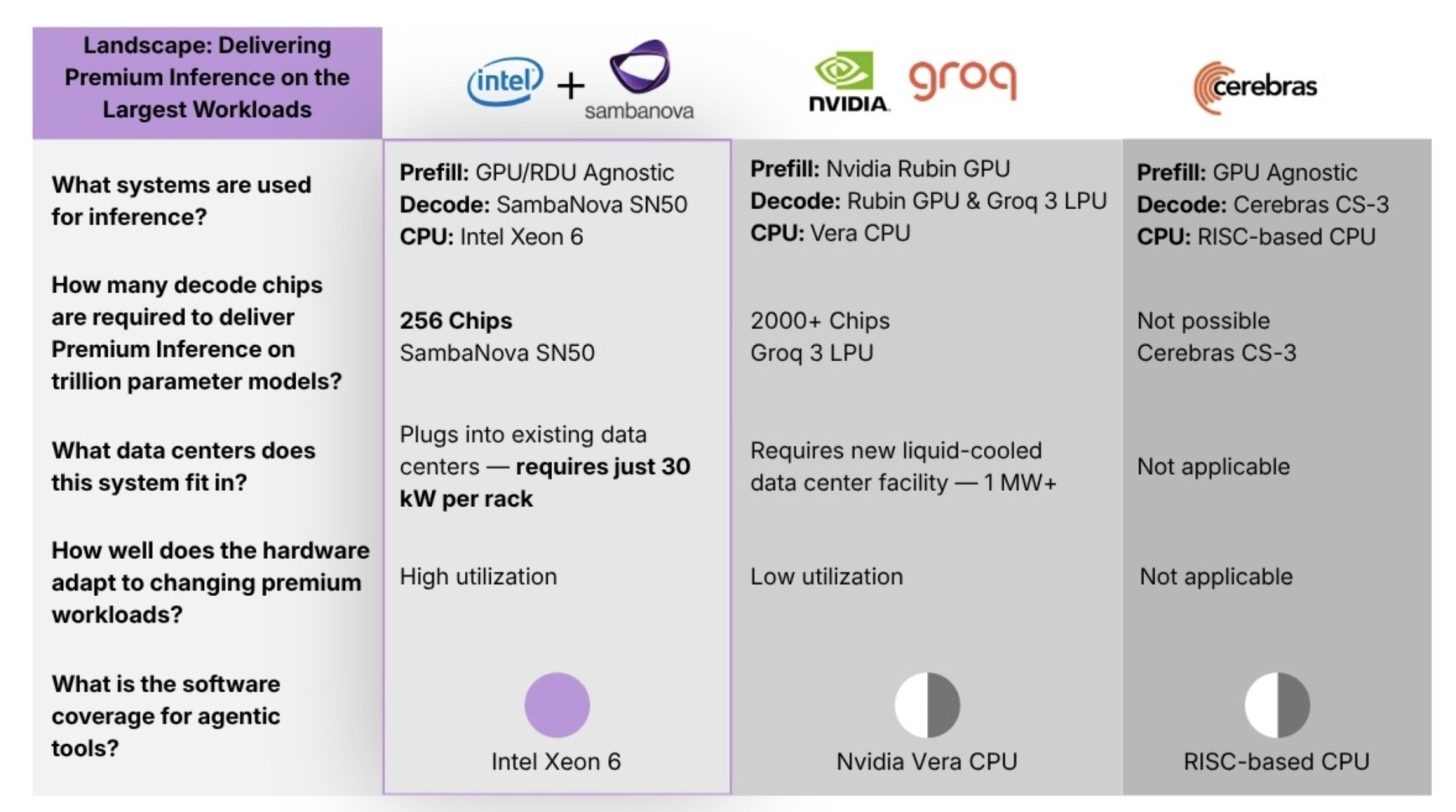
In the Intel and SambaNova design, the division of labor is clear. GPUs are assigned to prefill, which is the front loaded processing stage that handles large prompt ingestion and context setup. SambaNova RDUs take over decode, the stage where low latency token generation becomes critical. Xeon 6 then acts as both the host CPU and the action CPU, handling orchestration and the general purpose tasks that sit around the inference path. Intel says this is meant to address performance, efficiency, and software compatibility challenges for enterprises and cloud providers, while SambaNova says it is targeting premium inference for demanding Agentic AI applications.
The hardware centerpiece on SambaNova’s side is the SN50, its fifth generation RDU announced in February 2026. SambaNova says the SN50 is purpose built for agentic inference and built around a three tier memory architecture combining DDR5, HBM, and SRAM. The company says this design is intended to reduce latency, improve throughput, and keep more model state resident on chip or close to it for faster inference behavior. SambaNova also markets the design as enabling what it calls agentic caching.
On capacity and configuration, current reporting and SambaNova’s own launch material indicate the SN50 platform includes 2 TB of DDR5 memory, 64 GB of HBM, and a large SRAM pool, though third party technical reporting differs on the exact SRAM figure across package and chiplet views. Because of that, the safest confirmed description is that the SN50 uses a three layer memory hierarchy with very large DDR5 capacity, 64 GB HBM, and substantial on chip SRAM rather than pinning the article to a single SRAM number without a primary specification sheet in front of us.
There is also a practical business angle here. Unlike NVIDIA’s vertically integrated rack scale model, the Intel and SambaNova approach appears more modular. The partnership announcement does not lock customers into one specific GPU vendor for the prefill side, and the messaging around the blueprint focuses more on a flexible heterogeneous design than on an all in one proprietary platform. That gives the Intel and SambaNova pairing a potentially attractive position for operators who want disaggregated inference without buying into a single tightly controlled infrastructure stack. This is an inference based on the official architecture description and the absence of a single mandated GPU path in the announcement.
Intel’s role here is also notable because it extends beyond CPUs. Reuters reported on April 1, 2026 that Intel plans to invest an additional 15 million dollars into SambaNova, increasing its ownership stake, after a previous 35 million dollar investment in February 2026. Reuters also reported that Intel CEO Lip Bu Tan is chairman of SambaNova and that Intel had previously explored an acquisition of the company before that effort stalled. That gives the new collaboration extra weight, because it is not just a technical integration but part of a deeper strategic relationship.

The more important industry takeaway is that inference is no longer being treated as a simple extension of training infrastructure. The largest players in AI hardware are increasingly splitting inference into specialized stages, especially for agentic systems where fast response, persistent context, and efficient decode matter more than raw training scale. NVIDIA’s Groq linked LPX strategy and Intel’s SambaNova linked RDU strategy are 2 different answers to the same market reality: GPUs alone are no longer the whole story for premium inference.
For Intel, this is also one of the more credible AI infrastructure moves it has made recently. Rather than trying to force a full stack win with only in house silicon, it is attaching Xeon 6 to a workload where CPUs still matter, control, orchestration, and general purpose execution, while letting a specialized partner accelerator handle the part of the pipeline where it claims an architectural advantage. That is a more pragmatic posture, and in the inference market right now, pragmatism may be more valuable than trying to copy NVIDIA head on. This sentence is analysis based on the announced division of labor and current market positioning.
If this model works, the real competition in AI inference may become less about who has the single best chip and more about who can assemble the best prefill, decode, and orchestration stack at scale.
What do you think will matter more for next generation AI infrastructure: the strongest GPU, or the smartest heterogeneous system around it?