
NVIDIA’s RTX PRO 6000 Nearly Matches 4 RTX 5090s on MiniMax M2.7 While Using Far Less Power

A new local AI benchmark making the rounds in the enthusiast space is turning heads for one simple reason: a single NVIDIA RTX PRO 6000 Blackwell workstation GPU came remarkably close to matching a 4 GPU GeForce RTX 5090 setup on a 230 billion parameter MiniMax M2.7 model, while drawing dramatically less power. The benchmark was shared by Steveibe on X, and the model used for testing was MiniMax M2.7, which MiniMax describes as a 230B class model.
MiniMax M2.7 is 230B params. Can you actually run it at home?
— stevibe (@stevibe) April 18, 2026
I tested Unsloth's UD-IQ3_XXS (80GB) on 4 different rigs:
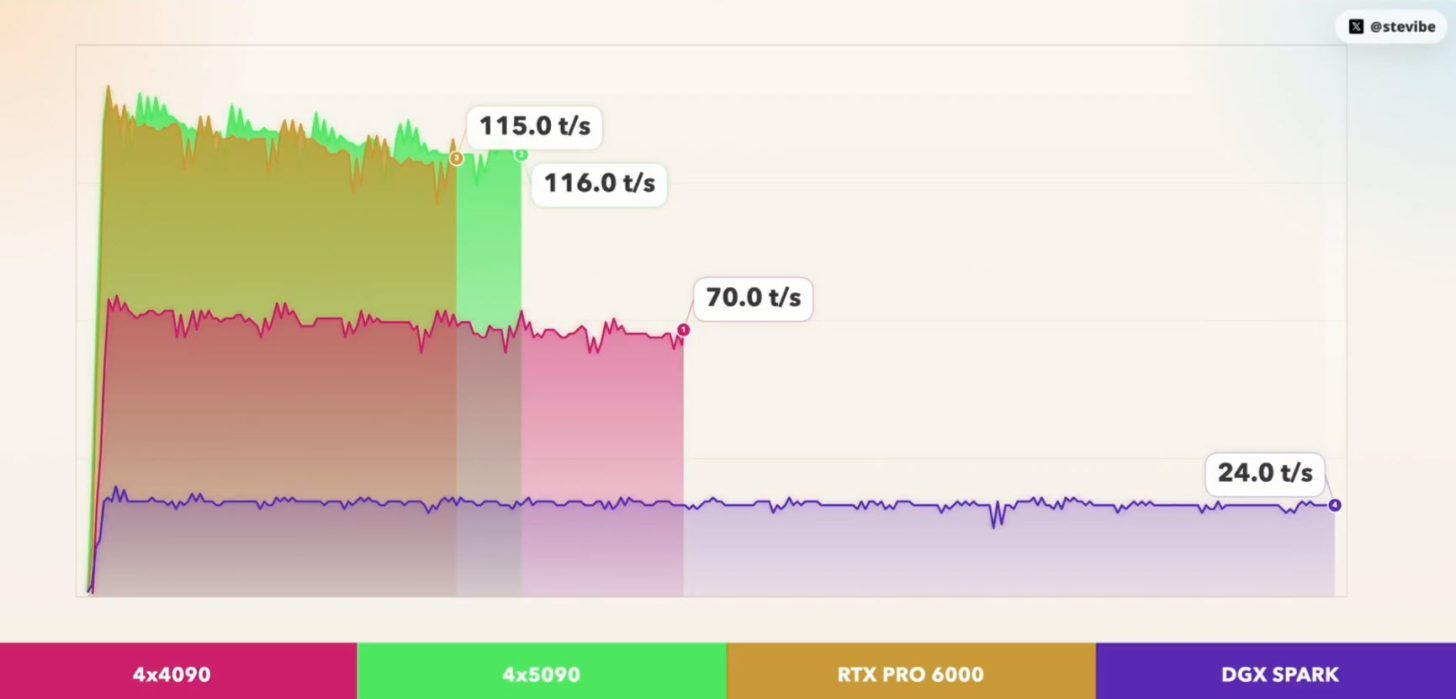
🟠 4x RTX 4090 (96GB): 71.52 tok/s, TTFT 1045ms
🟢 4x RTX 5090 (128GB): 120.54 tok/s, TTFT 725ms
🟡 1x RTX PRO 6000 (96GB): 118.74 tok/s, TTFT 765ms
🟣 DGX… pic.twitter.com/yK8bGg6RtX
According to the posted results, all 4 systems ran the same IQ3_XXS GGUF quantization, using a 32K context size and 4096 max tokens. The reported numbers were striking. The 4 x RTX 4090 setup reached 71.52 tok/s with 1045ms TTFT, the 4 x RTX 5090 setup reached 120.54 tok/s with 725ms TTFT, and the single RTX PRO 6000 96GB delivered 118.74 tok/s with 765ms TTFT. A DGX Spark system, also included in the comparison, reached 24.41 tok/s with 741ms TTFT. On raw generation speed alone, that places the single RTX PRO 6000 almost level with the 4 card RTX 5090 machine in this specific workload.
What makes the result more interesting is that this is not simply a VRAM story. NVIDIA’s official RTX PRO 6000 Blackwell product material says the card carries 96GB of memory, while NVIDIA’s DGX Spark product page lists 128GB of unified system memory for that platform. In other words, the benchmark is not comparing tiny cards against a giant workstation part. It is comparing very different hardware layouts and showing that, at least in this quantized local inference case, a single large memory professional GPU can avoid the multi GPU overhead that normally comes with trying to stitch multiple consumer cards together.
The power angle is where the comparison becomes especially compelling. The benchmark figures cited 1800W for the 4 x RTX 4090 configuration, 2300W for the 4 x RTX 5090 configuration, and 600W for the single RTX PRO 6000. NVIDIA’s own product information aligns with that ceiling on the workstation card, listing the RTX PRO 6000 Blackwell Workstation Edition at 600W max graphics power. If the posted test conditions are representative, then the RTX PRO 6000 is delivering roughly the same model throughput as the 4 x RTX 5090 machine while using roughly one quarter of the power.
That does not automatically mean the RTX PRO 6000 is the better buy for every user. The result is still based on one benchmark suite, one quantization choice, and one model family, not a full market wide inference leaderboard. It also does not erase the fact that consumer GPUs remain more familiar and often more flexible for gamers or mixed use PC builders. But for serious local AI users chasing very large model performance at home, this result is a strong reminder that single card efficiency and simplicity can matter just as much as brute force aggregate compute.
There is also a practical engineering lesson here. Multi GPU setups can absolutely unlock large model execution, but they often pay a penalty in synchronization, routing, memory coordination, and communication overhead. A single 96GB workstation card avoids much of that complexity. That likely helps explain why the RTX PRO 6000 got so close to the 4 x RTX 5090 result despite the huge apparent gap in total system hardware. In local inference, elegant memory fit can sometimes beat a more chaotic pile of raw silicon.
The DGX Spark result is also worth noting, even though it was much slower in tokens per second. NVIDIA positions DGX Spark as a personal AI supercomputer class system, and its official materials emphasize compact deployment, unified memory, and desktop form factor rather than pure peak token throughput. That makes it a very different proposition from a giant workstation GPU or a 4 card tower, and the posted result reflects that difference clearly.
Avg RTX 4090 Retail Price - $3000 US (Per GPU)
Avg RTX 5090 Retail Price - $3500 US (Per GPU)
Avg RTX PRO 6000 Retail Price - $9500 US (Per GPU)
Avg DGX Spark AI PC Retail Price - $4699 US
The broader takeaway is simple. For local AI, especially with huge quantized models, the hardware conversation is shifting beyond gaming card tribalism. VRAM capacity, memory topology, communication overhead, and power efficiency are becoming the real differentiators. In this MiniMax M2.7 test, NVIDIA’s RTX PRO 6000 did not just perform well. It showed that one properly configured professional GPU can come very close to a far bigger consumer setup while being much easier to power and manage. That is a meaningful signal for anyone planning a serious home inference machine in 2026.
Would you rather build a local AI machine around one giant workstation GPU, or still go with multiple consumer cards for maximum flexibility?