
NVIDIA Beats Everyone to DeepSeek V4 With Day 0 Blackwell Support and Nearly 3,500 Tokens Per Second

DeepSeek V4 has officially arrived with major efficiency upgrades for long context AI inference, and NVIDIA is already moving fast with Day 0 support across its Blackwell platform. The new model family introduces massive 1 million token context support, a 1.6T parameter Pro model, and a smaller Flash variant built for higher speed workloads. For NVIDIA, the launch is also a showcase moment for Blackwell, NVFP4, and the company’s full AI software stack.
According to NVIDIA’s official DeepSeek V4 Blackwell support announcement, DeepSeek V4 includes 2 flagship models: DeepSeek V4 Pro and DeepSeek V4 Flash. DeepSeek V4 Pro is the largest model in the family, with 1.6T total parameters and 49B active parameters. DeepSeek V4 Flash is a smaller 284B parameter model with 13B active parameters, designed for faster and more efficient workloads. Both support up to a 1M token context window, which is especially important for long context coding, document analysis, retrieval, and agentic AI workflows.
| Specification | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| Modality | Text | Text |
| Total parameters | 1.6T | 284B |
| Active parameters | 49B | 13B |
| Context length | 1M tokens | 1M tokens |
| Max output length | Up to 384K tokens through DeepSeek API docs | Up to 384K tokens through DeepSeek API docs |
| Primary use cases | Advanced reasoning, coding, long-context agents | High-speed efficiency, chat, routing, summarization |
| License | MIT | High-speed efficiency, chat, routing, and summarization |
The headline efficiency improvement is significant. NVIDIA says DeepSeek V4 is designed to achieve a 73% reduction in per token inference FLOPs and a 90% reduction in KV cache memory burden compared with DeepSeek V3.2. That means the new model uses only 27% of the single token inference FLOPs and 10% of the KV cache compared with its predecessor. For AI infrastructure, especially at 1M token context lengths, this is a major development because KV cache memory is one of the largest bottlenecks in long context inference.
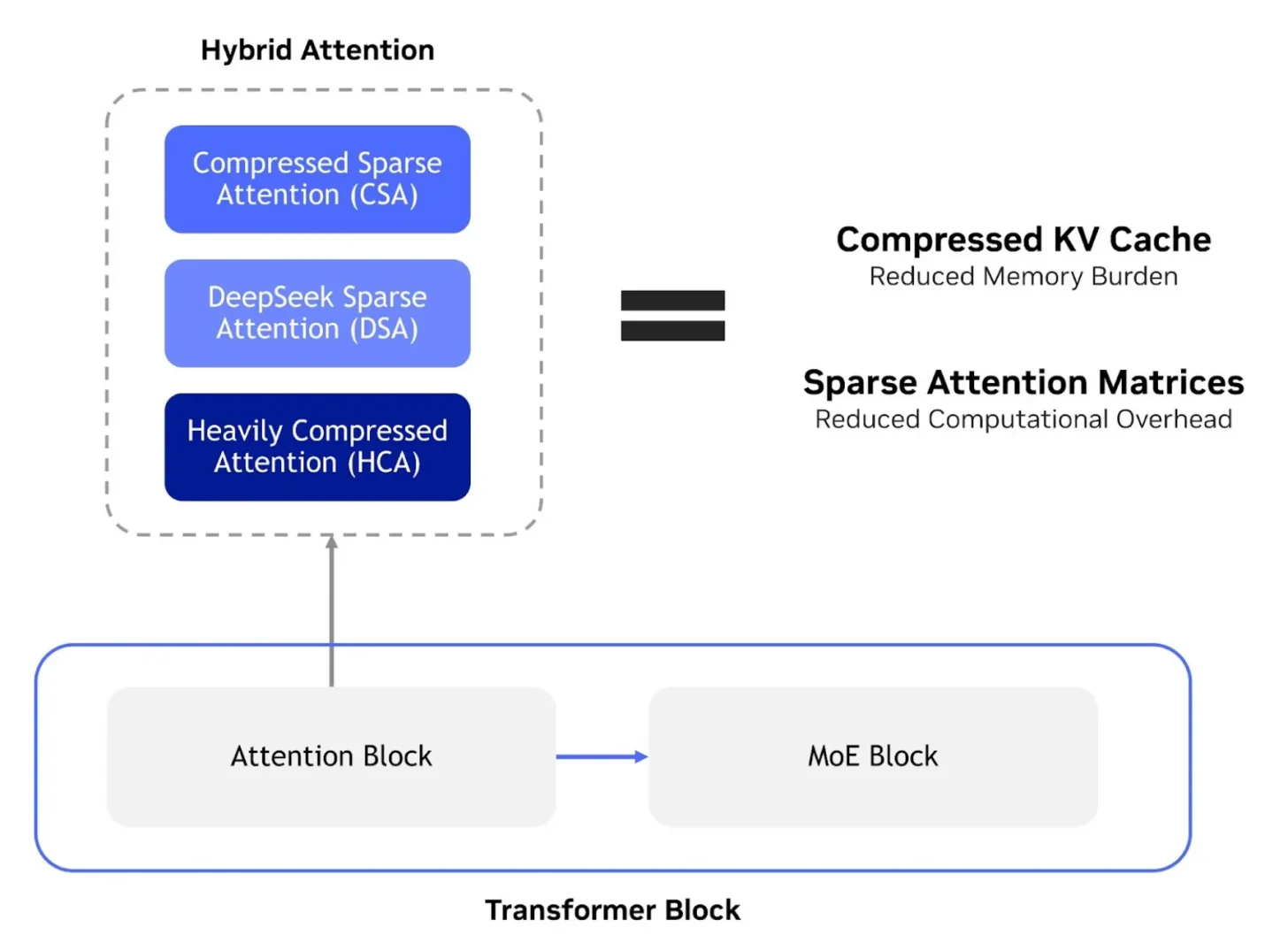
DeepSeek V4’s architecture uses a hybrid attention design that combines Compressed Sparse Attention, DeepSeek Sparse Attention, and Heavily Compressed Attention. The goal is to reduce both the KV cache footprint and the computational overhead inside the transformer block. This kind of optimization is becoming increasingly important as AI moves from basic chatbots toward agents that need to retain tool outputs, logs, retrieved documents, code, memory, and multi step reasoning across much longer workflows.
NVIDIA’s Day 0 support is where the hardware story becomes interesting. The company says Blackwell provides the scale and low latency performance needed for 1M long context inference and trillion parameter models. Out of the box tests on DeepSeek V4 Pro running on NVIDIA GB200 NVL72 reportedly delivered more than 150 tokens per second per user. NVIDIA also showed Blackwell B300 performance using the model’s native MXFP4 format, with the performance curve approaching nearly 3,500 tokens per second per GPU in high throughput conditions.
📊 Day 0 performance is here: DeepSeek-V4-Pro running on NVIDIA Blackwell Ultra.
— NVIDIA AI (@NVIDIAAI) April 24, 2026
Using @vllm_project's Day 0 recipe, we’ve captured the initial performance Pareto for DeepSeek’s flagship 1M long-context model. This curve highlights the baseline for balancing AI factory… pic.twitter.com/s6wi1Xvegj
The company is presenting these numbers as preliminary, with more performance improvements expected through optimization of the full co design stack. NVIDIA specifically pointed to Dynamo, NVFP4, optimized CUDA kernels, advanced parallelization techniques, and additional software stack improvements as areas where performance may continue climbing.
The role of low precision formats is central to this launch. DeepSeek V4 uses FP4 style quantization, including MXFP4, to reduce memory traffic and lower sampling latency during rollouts and inference passes. That matters because large models do not only need raw compute. They need efficient memory movement, reduced bandwidth pressure, and lower token generation cost. NVIDIA’s Blackwell platform was built with these low precision AI formats in mind, and the company is also promoting NVFP4 as part of its strategy for efficient and accurate low precision inference.

For developers, NVIDIA is making DeepSeek V4 available through GPU accelerated endpoints on build.nvidia.com as part of the NVIDIA Developer Program. DeepSeek V4 is also available on Day 0 with NVIDIA NIM, giving developers a faster path to deploy long context coding, document analysis, and agentic workflows through familiar API patterns. NVIDIA also highlights SGLang and vLLM support for DeepSeek V4 on Blackwell and Hopper, including serving recipes for different latency and throughput profiles, long context workloads, and prefill decode disaggregation.
This is important because AI model launches are no longer judged only by benchmark claims. The real competitive advantage now comes from how quickly models can be deployed, optimized, served, and scaled. NVIDIA’s ecosystem advantage is that it can support new open models immediately across hardware, CUDA kernels, inference frameworks, NIM microservices, and developer endpoints. That makes Day 0 support a business advantage, not just a technical milestone.
The DeepSeek V4 launch also has a broader geopolitical and hardware angle. Huawei’s upcoming Ascend 950PR and Ascend 950DT chips are reportedly expected to support MXFP4 instructions, which means DeepSeek V4 should also be compatible with China’s domestic AI chip ecosystem. That matters because China continues investing heavily in AI hardware independence, especially as access to leading NVIDIA accelerators remains restricted.
Even so, NVIDIA’s speed matters. By delivering Day 0 support and strong early throughput on Blackwell, NVIDIA is showing that it can remain the default platform for open model deployment even when models are developed outside the United States. DeepSeek V4 may support multiple hardware paths, but NVIDIA is already making the case that Blackwell will offer the fastest and most mature route for production deployment.

The key technical theme is clear: long context AI is becoming a full stack problem. DeepSeek V4 reduces FLOPs and KV cache pressure at the model architecture level. NVIDIA Blackwell accelerates low precision inference through hardware and software. Frameworks like vLLM and SGLang provide scalable serving paths. NIM and GPU accelerated endpoints give developers fast access. All of these layers matter if AI companies want to deploy 1M token agents at a practical cost.
For AI infrastructure buyers, DeepSeek V4 also reinforces why memory efficiency is becoming just as important as raw model size. A 1.6T parameter model with 1M token context is impressive, but it only becomes useful if it can run with acceptable latency, throughput, and cost. The 90% KV cache reduction is therefore one of the most meaningful parts of the launch because it directly targets the memory bottleneck that makes long context inference expensive.
There are still questions. NVIDIA’s figures are early out of the box results, not final optimized performance. DeepSeek V4’s aggressive compression also needs broader independent validation for quality, reliability, and long context recall. Reducing memory burden is valuable, but users will need to know whether the model can consistently retrieve precise information across massive contexts without missing critical details.
Still, the combination of DeepSeek V4 and NVIDIA Blackwell is a major signal for where AI is heading. The next wave of competition is not only about who has the biggest model or the fastest GPU. It is about which ecosystem can deliver the best token economics, the lowest latency, the strongest long context performance, and the fastest path from open model release to production deployment.
NVIDIA has made its position clear: when a major open model launches, Blackwell will be ready on Day 0.
Will DeepSeek V4’s memory efficient design and NVIDIA Blackwell’s FP4 acceleration make 1M token AI agents practical at scale?