
Taalas Claims 10x Higher TPS on Meta Llama 3.1 8B With 20x Lower Production Cost Using Model Specific ASIC Silicon

Taalas is making a bold claim in the fast moving AI infrastructure race, arguing it can deliver dramatically higher token per second throughput while cutting production cost by an order of magnitude by moving away from general purpose compute and toward model specific ASIC design. In a space where latency is increasingly the make or break constraint for agent style workloads, the company’s thesis is straightforward: if the moat is responsiveness, then optimizing the silicon for a specific model can beat scaling a flexible stack that spends too much time moving data around.
In its own technical positioning, Taalas says it has built a platform that can take a previously unseen AI model and realize it in hardware in as little as 2 months, producing what it calls Hardcore Models that are faster, cheaper, and lower power than software based implementations.
Taalas frames its strategy around 2 fundamentals.
First, specialization at the hardware level. Instead of treating AI inference as a workload you run on a flexible GPU style platform, Taalas describes mapping the neural network directly onto silicon and tuning the infrastructure for that specific model. This is effectively the opposite of the universal accelerator approach. The tradeoff is clear. You gain efficiency and speed, but you give up flexibility.

Second, merging storage and computation. The company argues that a large part of the latency wall comes from memory bottlenecks and data communication overhead inside general purpose systems. Taalas claims its solution keeps computation happening at DRAM level density to reduce intercommunication costs. It also emphasizes that it is not relying on advanced cooling, HBM, or complex packaging as the core differentiator, and that the innovation is concentrated in the silicon engineering itself.
The company’s first showcased product is HC1, which integrates Meta Llama 3.1 8B. Taalas claims HC1 delivers 10x the token per second of today’s high end infrastructure while achieving 20x lower production cost. If those ratios hold in real deployments, the implication is massive for any provider where response speed per dollar is the top KPI, especially for assistants and agent workflows where time to first token and sustained throughput directly affect perceived quality.
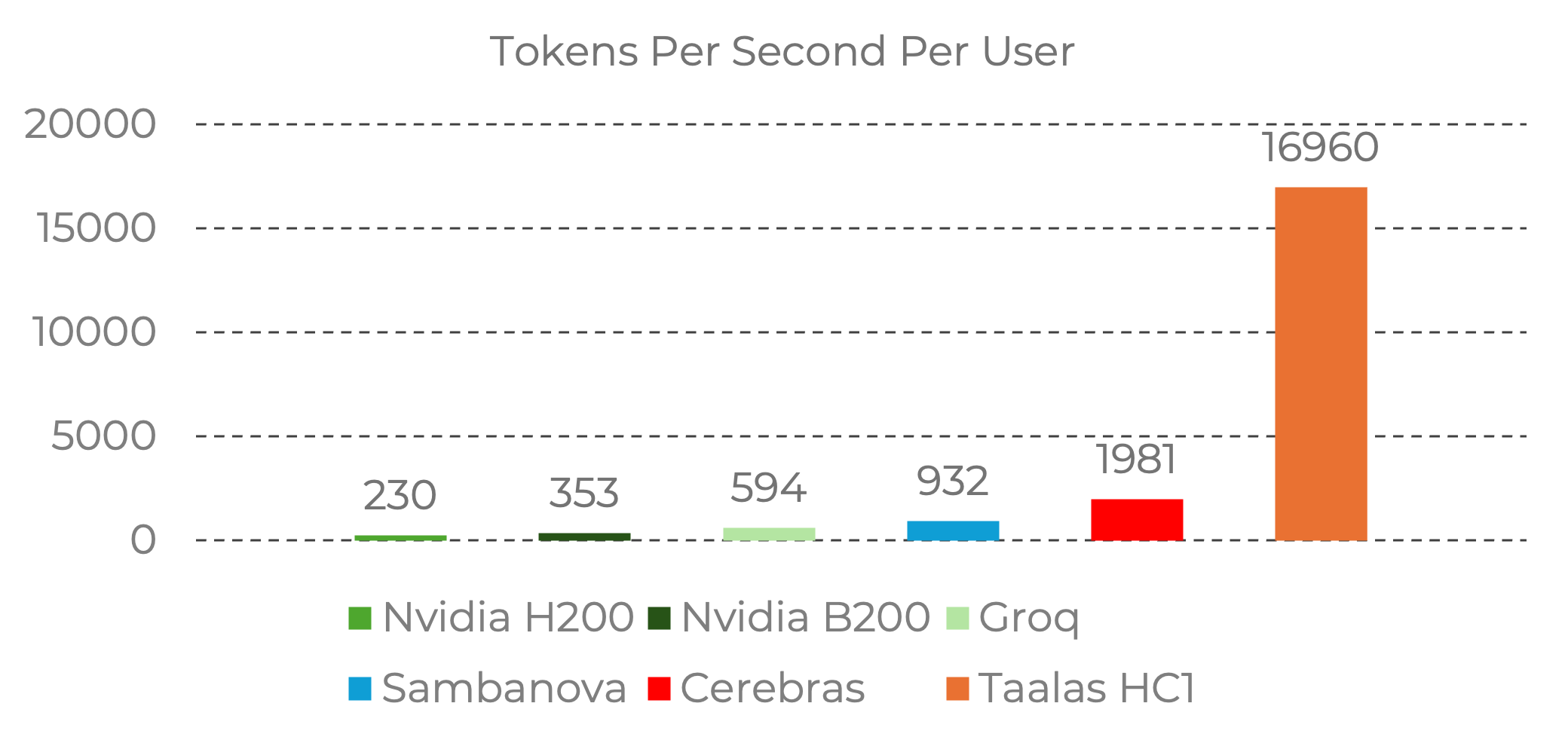
However, there is a scale reality check built into the same story. HC1 is described as using TSMC 6nm and reaching a die size up to 815 mm², which is an enormous piece of silicon for an 8 billion parameter class model, while the frontier model world is rapidly pushing into far larger parameter counts. That means the architecture either needs a clean scaling path through clustering, or it risks being boxed into a niche where it is unbeatable for specific mid size models but not competitive for the largest frontier deployments.
Taalas suggests it is already pursuing the clustering route. The company says it has demonstrated a 30 chip configuration for DeepSeek R1 that reaches 12000 TPS per user. If true, this reframes the problem from pure performance feasibility into market adoption and business model design. Hardwiring silicon to a model means you cannot simply swap weights and pivot instantly. The value proposition becomes a production pipeline that can refresh silicon quickly enough that model specificity is not a fatal limitation.
The big strategic question is whether the market is ready to treat model specific hardware as a recurring product cycle, similar to how game studios treat platform releases. If Taalas can truly go from model intake to hardware in 2 months at scale, the tradeoff of flexibility for speed might look less risky, especially in environments where a narrow set of models handle the bulk of production traffic.
Would you bet on model specific ASIC hardware like Taalas HC1 if it truly delivers 10x TPS and 20x lower cost, or is the loss of model flexibility a deal breaker for real world production workflows?