
Google Bets on the Agentic AI Era With Its AI Hypercomputer, Combining TPU 8t, TPU 8i, Axion, and NVIDIA Rubin

Google has officially expanded its AI Hypercomputer strategy at Google Cloud Next 2026, positioning it as the core infrastructure layer for what it calls the agentic era. In Google’s own announcement, the AI Hypercomputer now spans 2 new 8th generation TPUs, Arm based Axion CPUs, Virgo networking, high performance storage, and upcoming A5X bare metal instances powered by NVIDIA Vera Rubin NVL72. In other words, Google is not pitching a single chip launch here. It is pitching a full infrastructure stack designed to train, serve, and scale AI agents at hyperscale.

The company’s latest infrastructure update centers on 2 new custom TPU designs. Google says the TPU 8t is optimized for large scale training, while the TPU 8i is built for low latency inference and reasoning workloads. Google also says both chips were designed with Google DeepMind for the demands of agent based AI systems, where models must reason through multi step tasks and operate in continuous loops rather than simple one shot generation.
For training, Google says TPU 8t scales up to 9,600 TPUs and 2 petabytes of shared high bandwidth memory in a single superpod, delivering 3x the processing power of Ironwood and up to 2x better performance per watt. The broader AI Hypercomputer stack can then use Virgo Network to connect 134,000 TPUs in a single data center, and more than 1 million TPUs across multiple sites into a single logical training cluster. That is one of the clearest signs that Google is aiming directly at the frontier model training race rather than simply refreshing internal cloud silicon.
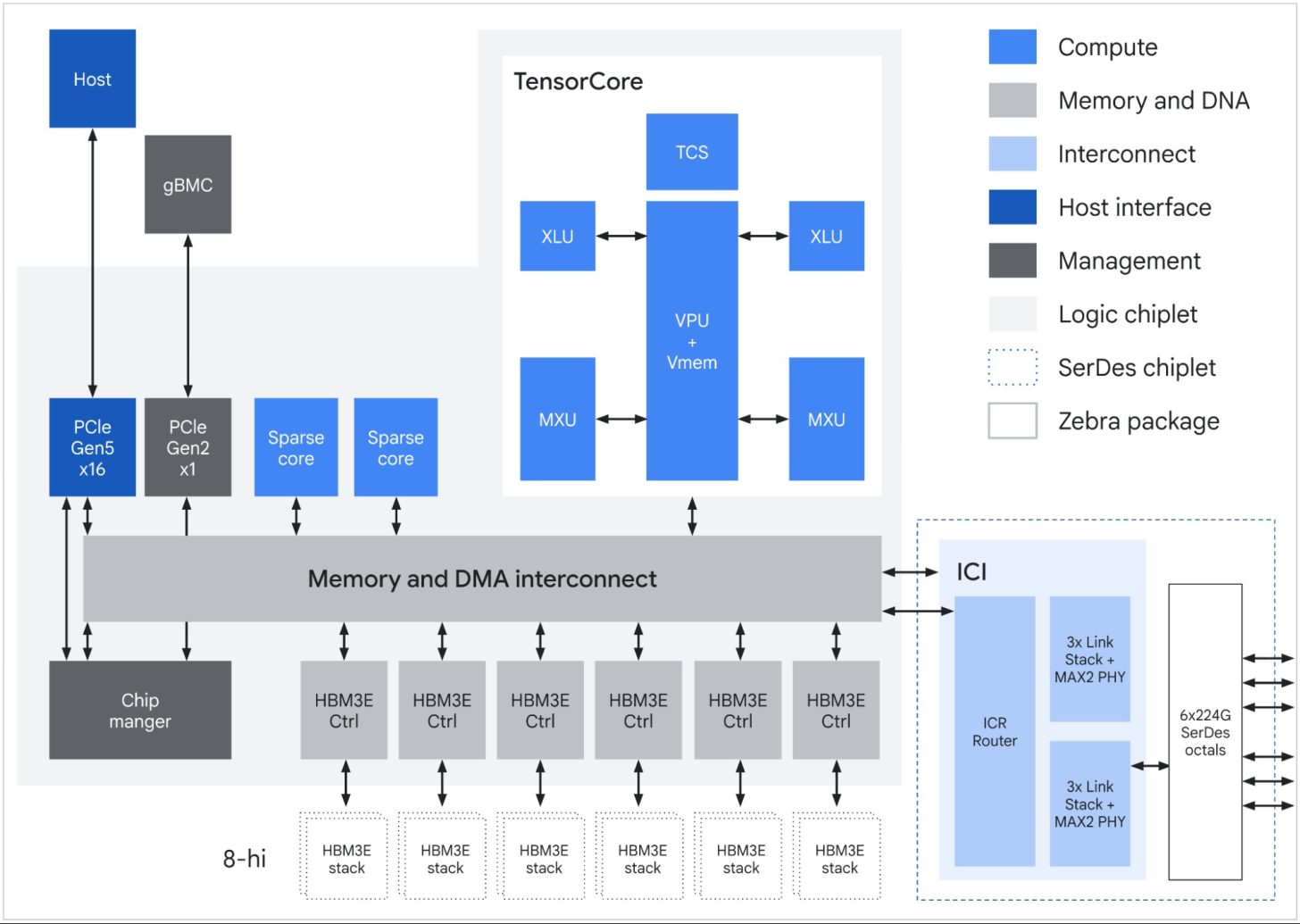
On the inference side, Google says TPU 8i uses a new Boardfly topology to directly connect 1,152 TPUs in a single pod, while increasing on chip SRAM and adding a Collectives Acceleration Engine for lower latency coordination. Google’s official recap says TPU 8i delivers 80% better performance per dollar for inference than the prior generation, with the design specifically targeted at fast, collaborative AI agents and large scale reasoning workloads.
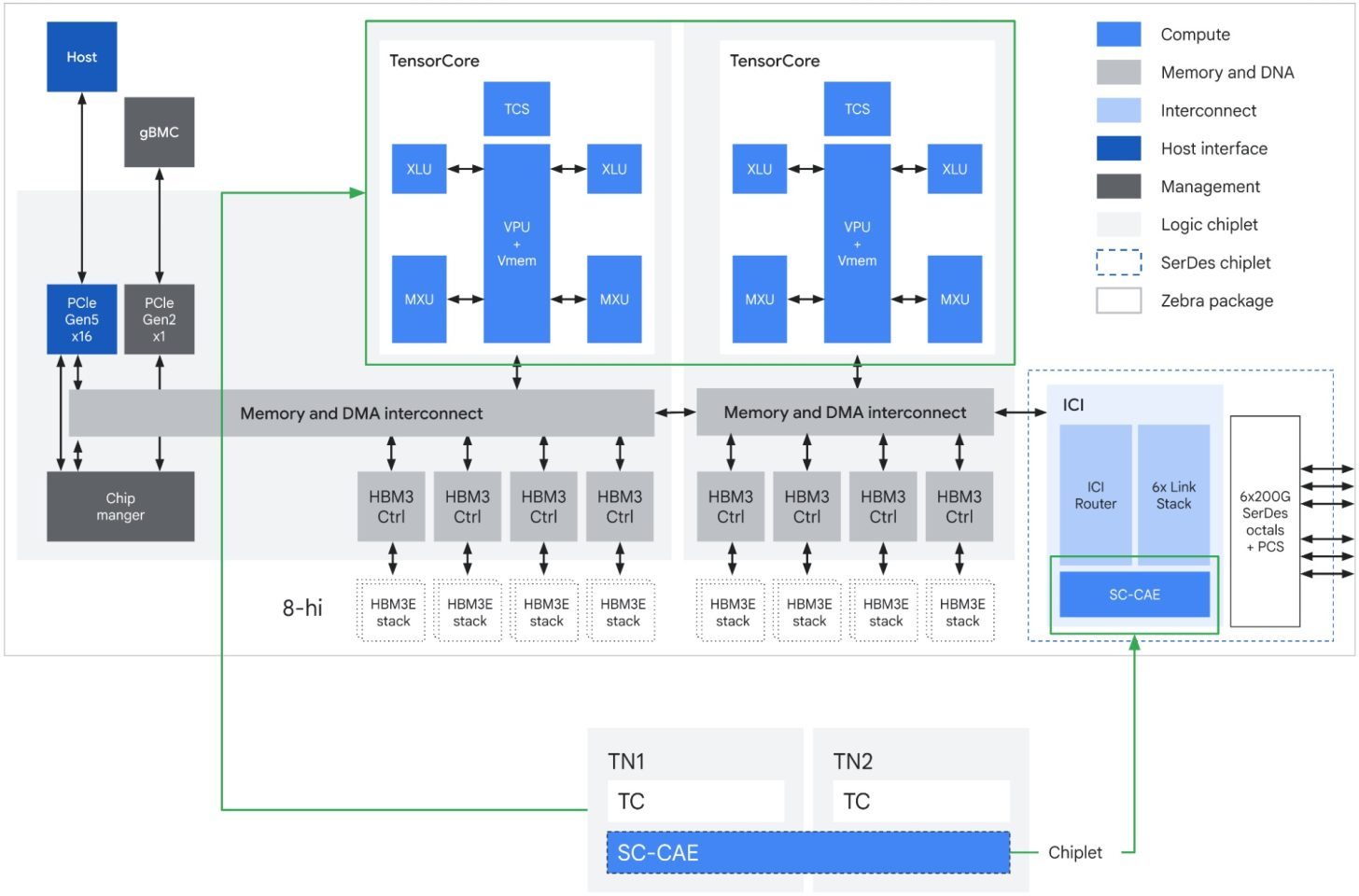
Google is also making it clear that the AI Hypercomputer is not TPU only. The company says it will be among the first cloud providers to offer NVIDIA Vera Rubin NVL72 through A5X bare metal instances, while also continuing to support Blackwell and Hopper based infrastructure. At the same time, the stack includes Axion N4A virtual machines based on Google’s custom Arm CPUs. Google’s January Axion update said N4A delivers up to 2x better price performance and 80% better performance per watt than comparable current generation x86 based VMs, while Google’s Next 2026 infrastructure recap positions Axion as part of the sustained compute layer for agentic workloads.
Google’s own AI infrastructure announcement and its earlier Axion N4A update together show the broader strategy clearly. This is a full stack push built around first party silicon where Google can, but still extending outward with NVIDIA where scale and customer demand justify it. That is especially important in the current market because enterprise AI customers are increasingly asking for flexibility across training, inference, and deployment, rather than locking themselves into a single compute path.
TPU 8t, optimized for training and TPU 8i, optimized for inference.
— Sundar Pichai (@sundarpichai) April 22, 2026
Looking good! pic.twitter.com/pTrblfF8mU
Google also tied the Hypercomputer announcement to supporting infrastructure outside the processors themselves. The company says Managed Lustre now delivers up to 10 TB per second of throughput for A5X or TPU 8t over RDMA, while Virgo Network is built to connect both TPU 8t superpods and Vera Rubin systems at massive scale. That means Google is framing AI Hypercomputer as a datacenter level architecture, not just a chip catalog. Storage, networking, and memory movement are being treated as first class components of the AI stack, which is exactly what the agentic AI workload pattern demands.
The larger business story matters too. Reuters reported that Google used Cloud Next 2026 to put AI agents at the center of its enterprise monetization strategy, with CEO Sundar Pichai reiterating that Alphabet plans to spend 175 billion dollars to 185 billion dollars on computing infrastructure this year, and that just over half of its machine learning compute investment will be dedicated to cloud. In that context, AI Hypercomputer is not just an engineering milestone. It is the infrastructure backbone Google hopes will turn the current wave of enterprise agent adoption into long term cloud revenue.
| Feature | TPU 8t | TPU 8i |
|---|---|---|
| Primary Workload | Large-scale pre-training | Sampling, serving, and reasoning |
| Network Topology | 3D torus | Boardfly |
| Specialized Chip Features | SparseCore (Embeddings) & LLM Decoder Engine | CAE (Collectives Acceleration Engine) |
| HBM Capacity | 216 GB | 288 GB |
| On-Chip SRAM (Vmem) | 128 MB | 384 MB |
| Peak FP4 PFLOPs | 12.6 | 10.1 |
| HBM Bandwidth | 6,528 GB/s | 8,601 GB/s (~1.3x of TPU 8t) |
| CPU Header | Arm Axion | Arm Axion |
What stands out most is that Google is now presenting the agentic AI era as an infrastructure problem as much as a model problem. Faster chips alone are not enough. The company is betting that training clusters, inference silicon, Arm based CPUs, high throughput storage, and datacenter scale networking all need to be co designed into one environment. In that sense, AI Hypercomputer is Google’s answer to the same full stack AI race that NVIDIA, Microsoft, Amazon, and OpenAI are all now trying to define in their own way.
What do you think will matter more in the next AI infrastructure wave: better custom TPUs, broader GPU access, or whoever builds the strongest full stack around both?