
NVIDIA Software Cuts DeepSeek V4 Inference Cost by Up to 5x on Blackwell

NVIDIA says continued software optimization has reduced the cost of serving DeepSeek V4 on its Blackwell platform to roughly one fifth of its initial level within about 1 month, highlighting how rapidly inference economics can improve after a major artificial intelligence model launches.
According to NVIDIA’s official inference software announcement, the improvement was achieved through coordinated work across model serving, runtime scheduling, communication libraries, numerical precision, memory management, and hardware aware kernels. The company says its broader objective is to maximize the number of useful tokens generated for every dollar and watt while maintaining the latency required by users.
The result does not represent a direct reduction in an NVIDIA retail token price. NVIDIA sells processors, networking, software, and complete systems rather than operating one universal DeepSeek application programming interface. The cost figure is based on infrastructure economics measured through the SemiAnalysis InferenceX framework, which estimates performance per dollar using hardware costs, throughput, model configuration, and interactivity targets. Different context lengths, batch sizes, precision formats, serving frameworks, and latency requirements can produce substantially different results.
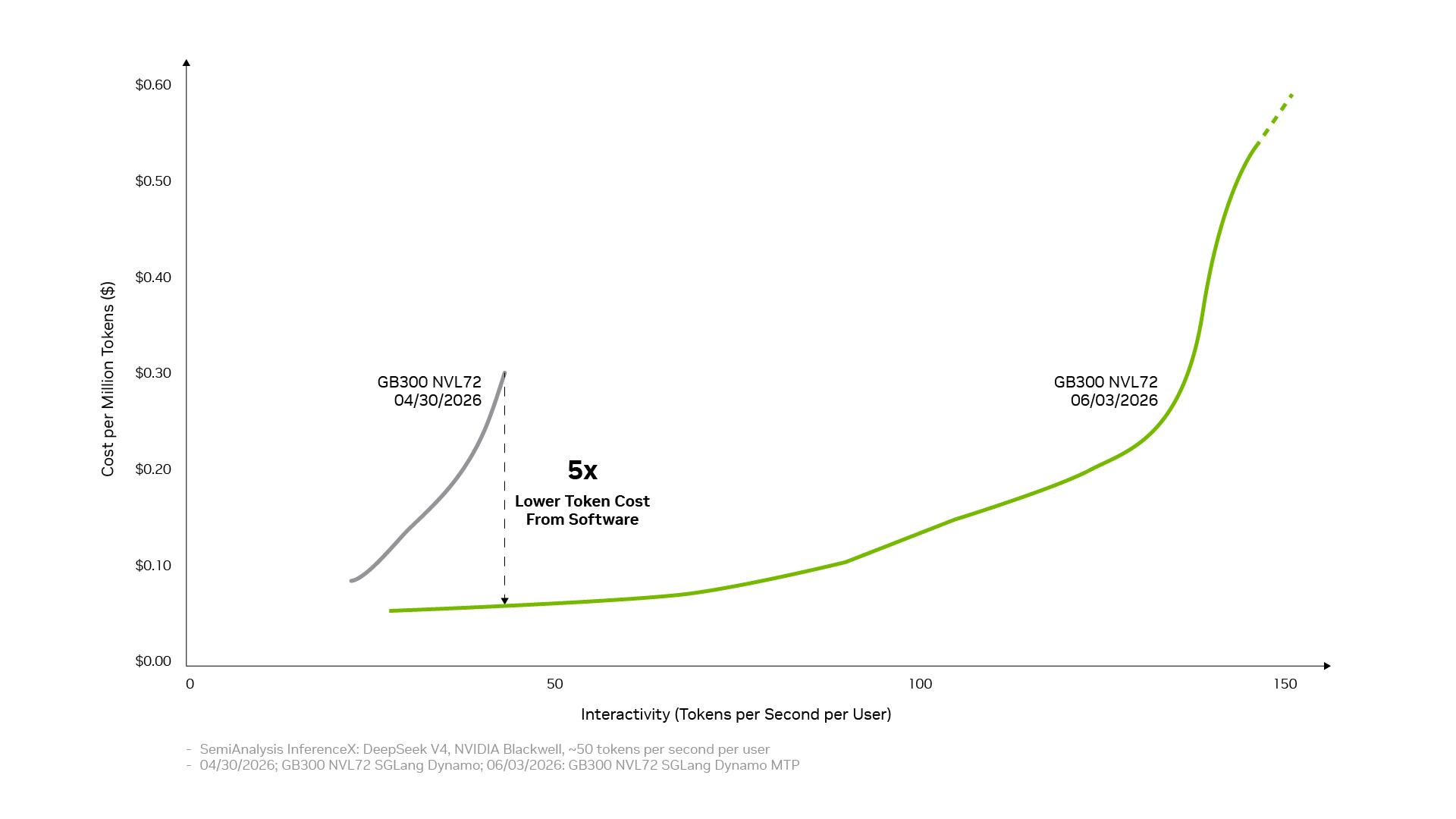
DeepSeek V4 is particularly demanding because its Pro version contains approximately 1.6 trillion total parameters and supports context windows reaching 1 million tokens. Its compressed attention architecture can reduce the amount of key value cache required for long prompts, but the practical benefit depends on how effectively the inference engine handles several cache layouts, prefix reuse, batching, memory eviction, and distributed execution.
NVIDIA says Blackwell performance improved through contributions to both vLLM and SGLang, 2 widely used open source inference frameworks. The company provided deployment recipes for DeepSeek V4 from its release, including configurations for single node systems, deployments exceeding 100 GPUs, separate prefill and decode resources, speculative decoding, and long context workloads.
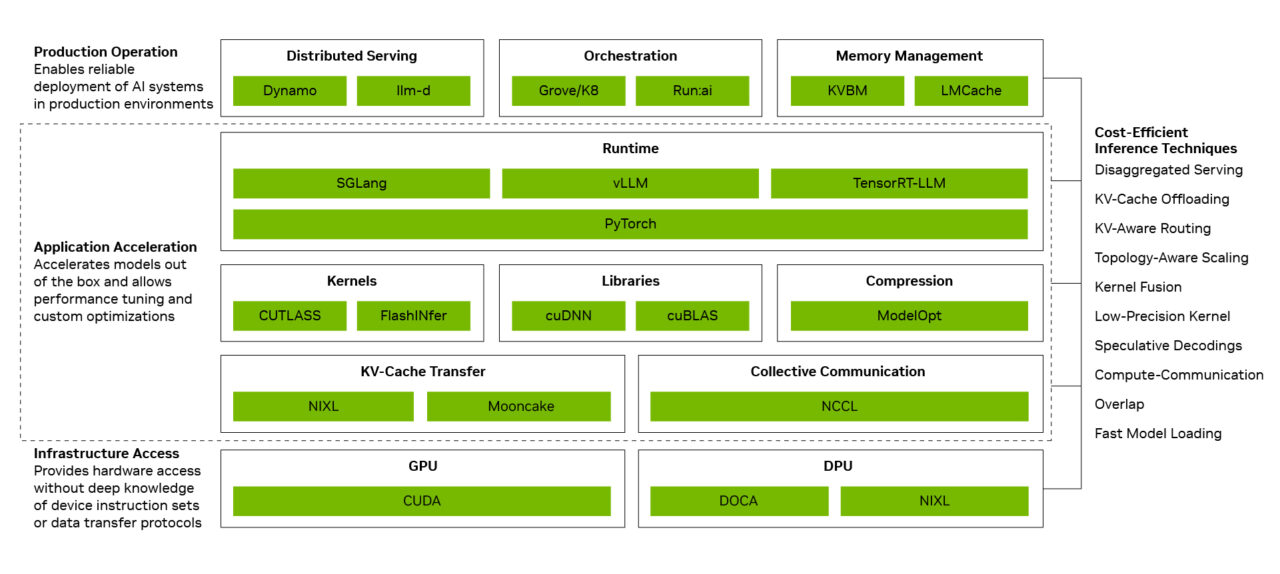
NVIDIA divides its inference software platform into 3 connected layers. Production Operation coordinates distributed serving, autoscaling, orchestration, memory allocation, and the assignment of workloads across compute and storage resources. Application Acceleration optimizes model execution through methods including kernel fusion and overlapping computation with communication. Infrastructure Access exposes the capabilities of NVIDIA GPUs, networking, memory, and rack scale systems without requiring developers to manage every low level instruction or transfer protocol directly.
The company says several individual technologies can produce a combined throughput improvement of up to 20x compared with a basic FP8 configuration. These include disaggregated serving, large expert parallelism across NVLink, NVFP4 numerical precision, and Multi Token Prediction. The 20x figure is separate from the 5x DeepSeek V4 cost improvement and represents the cumulative effect of several optimizations under NVIDIA’s selected throughput comparison.
Disaggregated serving separates prompt processing from token generation, allowing each stage to use a hardware configuration optimized for its own workload. Large expert parallelism distributes the experts inside mixture of experts models across many accelerators, while NVLink provides the communication bandwidth required to keep those processors synchronized. NVFP4 reduces memory and compute requirements through lower precision processing, and Multi Token Prediction allows a model to propose several future tokens rather than generating only 1 candidate during each step.
Several inference providers are already applying parts of this software stack. Baseten used TensorRT LLM to deploy DeepSeek V4 Pro on Blackwell for coding, reasoning, and long context workloads, combining NVIDIA software with its own runtime optimization to deliver up to 50% more tokens per second. Cognition is using NVIDIA Dynamo to manage accelerator resources for reinforcement learning workloads without constructing its complete distributed inference system internally.
DeepInfra says its platform combines Blackwell B300 GPUs, TensorRT LLM, Dynamo, ModelOpt, and NVFP4. The company reported that a DeepSeek V4 workload previously requiring 4 H200 GPUs could run on 1 B300 while delivering higher token throughput. This is a provider supplied comparison and may not apply to every workload or latency target.
NVIDIA also says Together AI used TensorRT LLM on Blackwell to help Cursor move model optimizations into production endpoints for responsive coding tools. DigitalOcean and Hippocratic AI reported a 30% increase in inference throughput while maintaining a response time below 0.5 seconds across a system supporting 10 million patient calls.

The results support NVIDIA’s argument that artificial intelligence infrastructure should be evaluated through complete system economics instead of theoretical processor performance alone. A GPU can offer high peak compute while delivering weaker production efficiency if scheduling, memory usage, communication, or thermal behavior prevents the system from sustaining that performance.
This direction is also visible in previous analysis of the NVIDIA GB300 AgentPerf results, where Blackwell Ultra supported substantially more concurrent DeepSeek V4 agents per GPU and per megawatt than H200 under NVIDIA’s selected benchmark configuration. The result showed why agent capacity, power usage, latency, and cost are becoming more commercially important than peak floating point figures alone.
Competition is also increasing Tensordyne’s Napier inference processor examined a new architecture claiming higher token throughput and efficiency than GB300. Those figures remain based on internal simulations, but they demonstrate why NVIDIA is placing so much emphasis on continuous software improvement. New accelerators are increasingly being marketed around tokens per watt and tokens per dollar rather than traditional chip specifications.
The most important part of NVIDIA’s announcement is not the 5x figure by itself. It is the speed at which software optimization changed the economics of hardware that was already deployed.
AI accelerators are no longer static products whose performance is fixed when they leave the factory. Improvements to kernels, precision formats, model routing, cache management, communication, and orchestration can substantially increase the useful output of the same system after installation.
That creates a powerful advantage for NVIDIA. CUDA, TensorRT LLM, Dynamo, NVLink, vLLM, SGLang, and the wider developer ecosystem allow optimization work from many organizations to compound across the Blackwell platform. Customers may receive higher performance from existing infrastructure without replacing the processors.
The caution is that cost per token cannot be reduced to 1 universal number. Model architecture, prompt length, output length, concurrency, latency, power pricing, hardware utilization, and infrastructure ownership all influence the final cost. NVIDIA’s result is significant, but buyers should compare systems using their own production traffic rather than a single selected benchmark point.
Will software optimization become more important than raw accelerator specifications as companies compete to deliver the lowest artificial intelligence inference cost?