
NVIDIA Delivers A Free RTX AI Performance Upgrade With Faster LLMs, Native NVFP4 In ComfyUI, And New Creator Features For Video And Search

NVIDIA is continuing its push to make RTX PCs the premium local AI and creator platform by rolling out a new Free RTX AI Performance Upgrade that targets two of the biggest pain points for on device workflows: large language model responsiveness and generative creation throughput. NVIDIA frames this as the next step in a multi year acceleration arc that started with TensorRT LLM for Windows 11 in 2023 with a 5x boost, followed by an additional 3x uplift in 2024 for AI workloads. Now, the 2026 update focuses on measurable gains across popular LLM runtimes and creator pipelines, with NVFP4 and NVFP8 enabling a more datacenter style precision approach on consumer RTX hardware.
The first part of the upgrade is focused on faster LLM performance, with NVIDIA stating up to 40% higher performance in models such as GPT OSS, Nemotron Nano V2, and Sque 3 308. In practical terms, this kind of uplift matters most in interactive sessions where token throughput and latency define the experience, especially when developers are iterating on prompts, testing tool calls, or running local agent style workflows that rely on consistent responsiveness. For creator users, it also improves the experience of AI assisted scripting, storyboarding, and asset planning where shorter iteration loops translate directly into higher output.
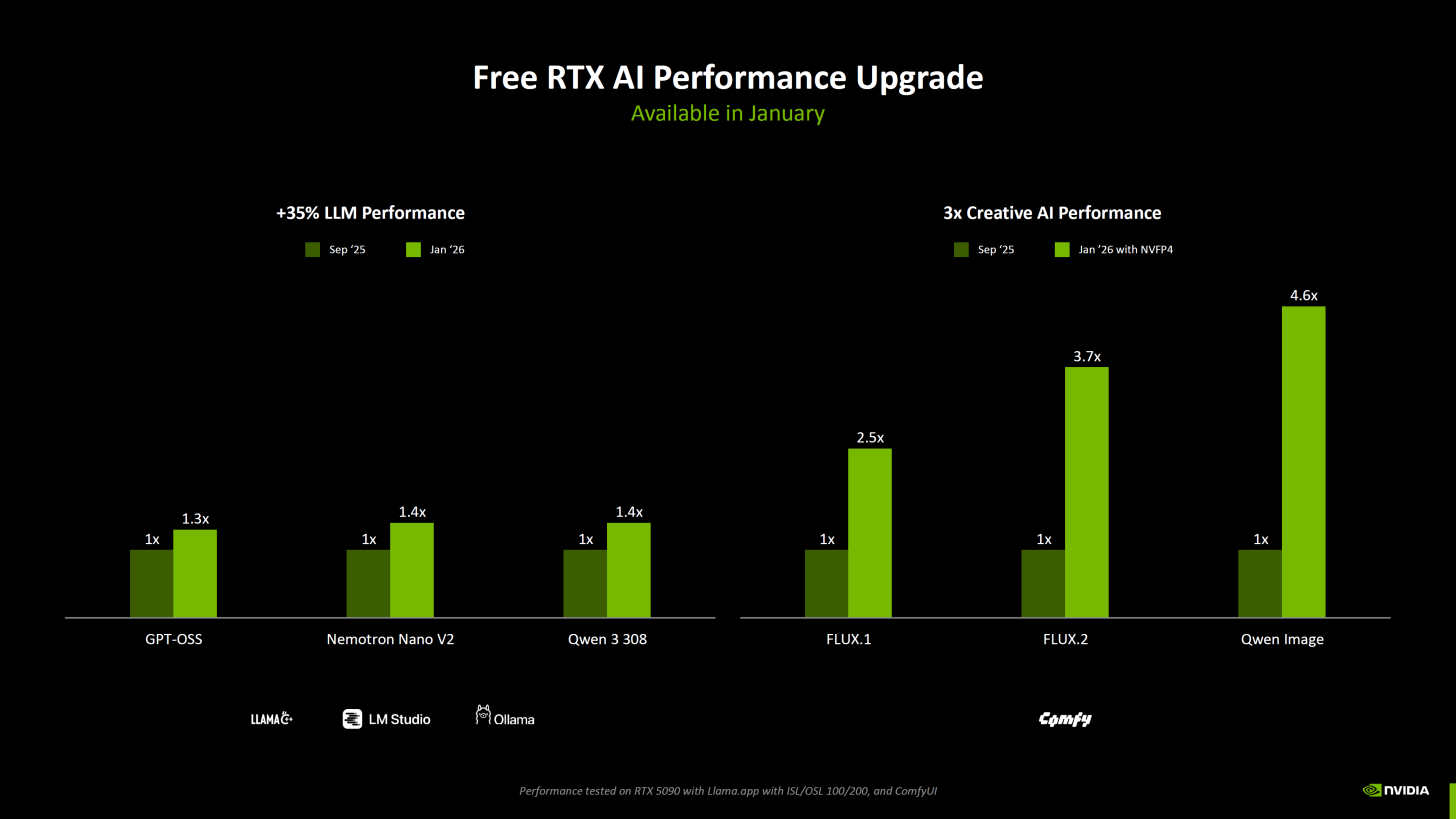
The second part is a creator focused leap that enables native NVFP4 support in ComfyUI for Flux.1, Flux.2, and Qwen Image. NVIDIA claims this yields up to 4.6x performance gains, turning high quality image generation and advanced pipeline workflows into something that can run far faster on RTX PCs without requiring cloud compute for every iteration. This is an important strategic move because ComfyUI has become a core tool for creators building modular generative workflows, and native precision support directly impacts how quickly users can prototype prompts, run batch variations, and refine final outputs.

One of the more operationally meaningful improvements NVIDIA highlights is that native NVFP4 and NVFP8 support is not only landing for up to 60% smaller LLMs, but it also enables offloading to system memory, which can free up graphics resources. The platform benefit here is a better balance between VRAM constrained workloads and system memory usage, helping RTX PCs run heavier pipelines with fewer memory bottlenecks. NVIDIA also emphasizes that NVFP4 reduces VRAM usage significantly versus BF16 instructions in the referenced Flux and Qwen Image workloads, which is a direct quality of life upgrade for creators running large models, high resolution generations, or multi stage workflows.
NVIDIA is also extending the RTX AI PC value proposition with new video creation capabilities. One highlight is an Audio to Video model called LTX 2, described as the number 1 open weights video model on the market, capable of 4K video generation in 20 seconds. NVIDIA states that with NVFP8 support, users can see up to a 2.0x performance gain, positioning RTX PCs as increasingly viable for fast local video ideation and concept generation, especially for social content, motion experiments, and rapid creative prototyping.
On top of model acceleration, NVIDIA is bringing Super Resolution support to GenAI videos through RTX Video. This update is described as landing on ComfyUI in February, and it enables upscaling 720p GenAI videos to 4K for improved quality and detail. NVIDIA also provides an end to end workflow time comparison: generating a 4K 10 second video using NVFP8 plus Super Resolution takes 3 minutes versus 15 minutes with the older method. That is the kind of delta that changes behavior because it shifts video generation from a high friction background task into a workflow you can iterate on multiple times in a single session.

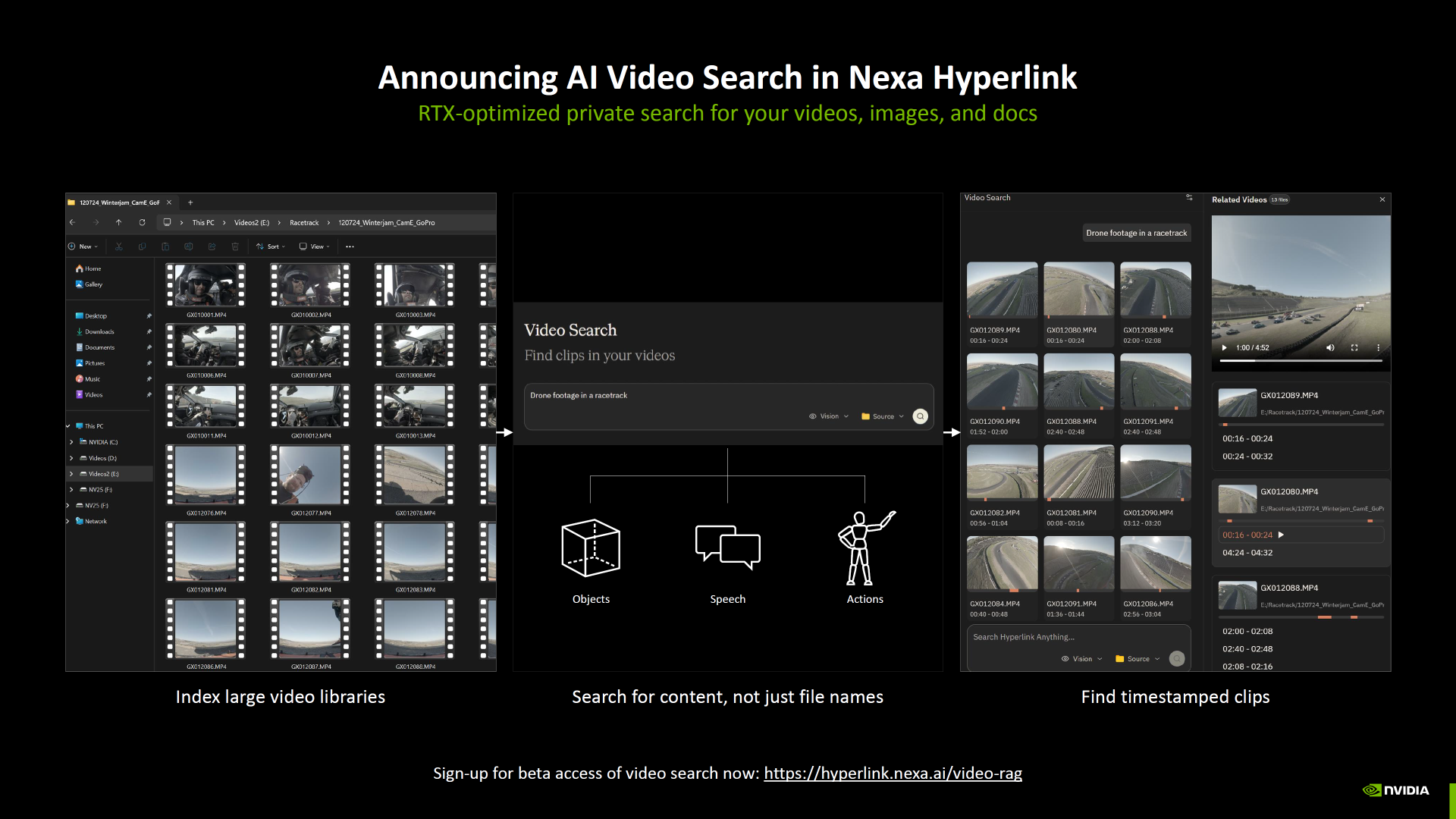
Finally, NVIDIA is expanding into content discovery with AI Video Search coming to Nexa Hyperlink, enabling an RTX optimized private search experience for videos, images, and documents. This speaks to a broader platform strategy where RTX PCs are not only about generating content, but also about managing and retrieving it locally, with privacy and ownership positioned as differentiators versus purely cloud based toolchains.


Taken together, these updates reinforce a forward looking positioning for RTX PCs: continuous software driven uplift, better precision formats for real performance gains, and creator centric features that reduce time to output. For gamers who also create, mod, or build content pipelines, this is NVIDIA treating the RTX PC as a multi role machine that can game at night and produce at scale during the day, with each update compounding the value of the hardware already on the desk.
Which upgrade matters more to your workflow, up to 40% faster local LLM performance, or up to 4.6x faster ComfyUI generation with NVFP4 and lower VRAM usage?