
OpenAI Unites AMD, NVIDIA, Intel, Microsoft, and Broadcom Around MRC to Scale AI Supercomputer Training

OpenAI has pulled together one of the most consequential infrastructure alliances in the AI industry, partnering with AMD, NVIDIA, Intel, Microsoft, and Broadcom to develop a new networking protocol called MRC, short for Multipath Reliable Connection. The goal is to improve performance and resilience in massive AI training clusters, where even a single delayed transfer can leave GPUs waiting idle and drag down efficiency across an entire job. OpenAI says it has now released MRC through the Open Compute Project so the broader industry can adopt and build on it.
This matters because networking is becoming one of the most critical bottlenecks in frontier model training. OpenAI explains that at large scale, congestion, link failures, and device failures become much more common, and those issues can ripple through synchronized training runs. MRC is OpenAI’s answer to that problem. The protocol is built into the latest 800 Gb/s network interfaces and is designed to spread a single transfer across hundreds of paths, reroute around failures in microseconds, and simplify the control plane compared with more conventional large cluster network designs.
We’ve partnered with @AMD, @Broadcom, @Intel, @Microsoft, and @NVIDIA, to release Multipath Reliable Connection (MRC), a new open networking protocol that helps large AI training clusters run faster and more reliably, with less wasted GPU time.https://t.co/AiV952AJXs
— OpenAI (@OpenAI) May 6, 2026
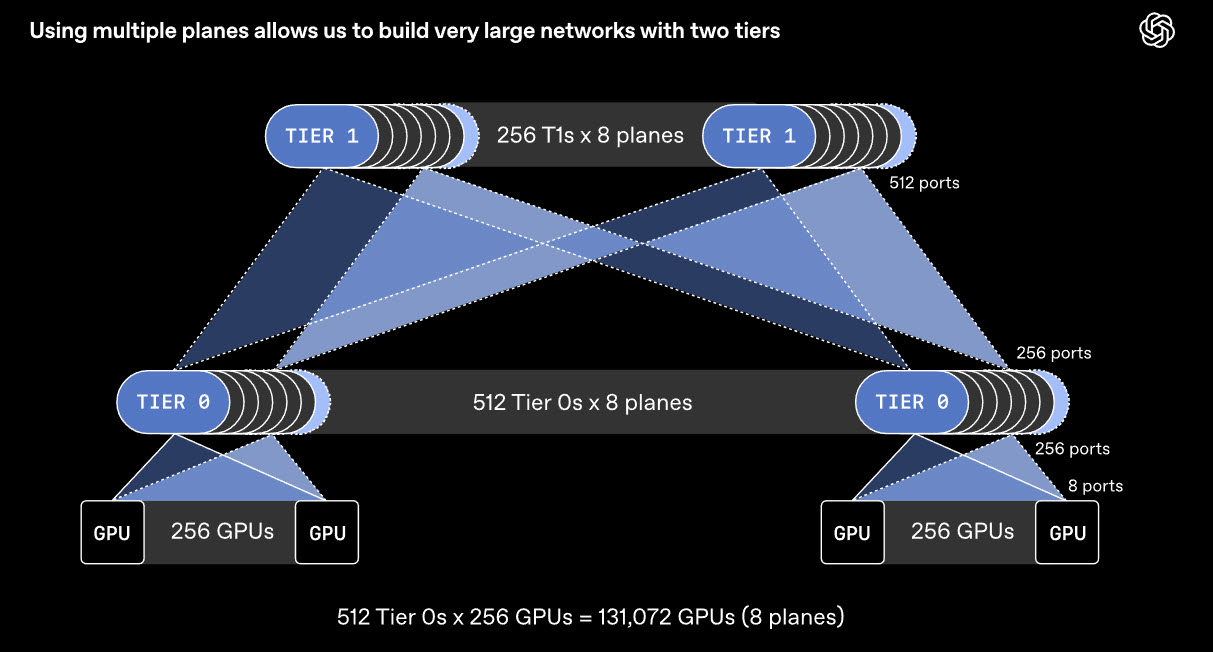
The technical idea behind MRC is both practical and ambitious. Instead of treating one 800 Gb/s interface as a single giant pipe, OpenAI says it can be divided into multiple smaller links, such as 8 separate 100 Gb/s connections. That lets operators build multiple parallel network planes, which dramatically changes the scale of the fabric. OpenAI says this approach can support a fully connected network of about 131,000 GPUs with only 2 tiers of switches, where a conventional 800 Gb/s network would typically need 3 or 4 tiers. That reduction in tiers can lower power use, reduce component count, and improve resilience at scale.
MRC also extends RDMA over Converged Ethernet, or RoCE, by combining packet spraying across multiple paths with SRv6 based source routing. In OpenAI’s description, that means packets from a single transfer can travel through many paths simultaneously, avoiding congestion hot spots and quickly dropping failed routes without waiting for traditional dynamic routing to stabilize. The company says this lets MRC react to network issues on a microsecond timescale rather than the seconds or tens of seconds conventional fabrics may need.
What makes the announcement especially notable is that this is not just a paper exercise. OpenAI says MRC is already deployed across all of its largest NVIDIA GB200 supercomputers used to train frontier models, including the Oracle Cloud Infrastructure site in Abilene, Texas, and Microsoft’s Fairwater supercomputers. It also says MRC has already been used to train multiple OpenAI models on hardware from NVIDIA and Broadcom. That gives the protocol much more weight than a standard draft specification, because it is already operating in real production class environments rather than waiting on future validation.
The partner announcements reinforce just how broad this effort is. AMD says MRC is helping enable scalable and resilient Ethernet based AI fabrics and frames the protocol as part of a more open networking foundation for future AI systems. AMD’s blog positions the work as a key step in making large scale AI networking more efficient and interoperable. NVIDIA’s Spectrum X announcement similarly ties MRC into its open Ethernet AI networking push, while Broadcom says in its own MRC post that the technology helps support AI networking at much larger scale. Microsoft also published its perspective in this Azure HPC post, underscoring the cloud infrastructure side of the partnership.
There is also an important correction to make in the broader discussion. The protocol is MRC, not RCP. OpenAI’s specification is published as the OCP MRC 1.0 PDF, and all of the official partner materials refer to Multipath Reliable Connection rather than any protocol called RCP.
Strategically, this may be one of the clearest signs yet that the AI industry is starting to coordinate around shared infrastructure standards where scale demands it. OpenAI says it worked with these partners over the past 2 years to create MRC, and releasing it openly through OCP signals that the company wants adoption beyond its own deployments. That could matter a great deal as larger AI clusters become more common, especially for companies that want Ethernet based alternatives with stronger openness and multi vendor compatibility. This last point is an inference based on OpenAI’s stated rationale for publishing the protocol and the breadth of vendor support behind it.
For OpenAI, MRC is not just another networking upgrade. It is becoming part of the foundation for Stargate era supercomputing, where model training depends on keeping enormous clusters moving predictably under constant load. If this protocol delivers at wider industry scale, it could end up being one of the more important invisible technologies behind the next generation of frontier AI systems.
What do you think will matter more for the next wave of frontier AI, faster chips or smarter large scale networking standards like MRC?