
NVIDIA Claims Blackwell Ultra Leads MLPerf v6.0 as Extreme Co Design Delivers Big DeepSeek Gains

NVIDIA is once again using MLPerf as a major proof point for its AI platform strategy, and this latest round focuses heavily on how software, system design, and Blackwell Ultra hardware are working together. In its new technical blog post, NVIDIA says its MLPerf Inference v6.0 submission delivers the highest AI factory throughput and lowest token cost across a broad set of modern workloads, including large language models, reasoning models, mixture of experts models, recommendation systems, and vision language applications. MLCommons’ own v6.0 update supports that broader framing, confirming that this benchmark round expands coverage with GPT OSS 120B and adds a latency constrained DeepSeek R1 interactive scenario, making the suite more representative of current enterprise AI deployments.
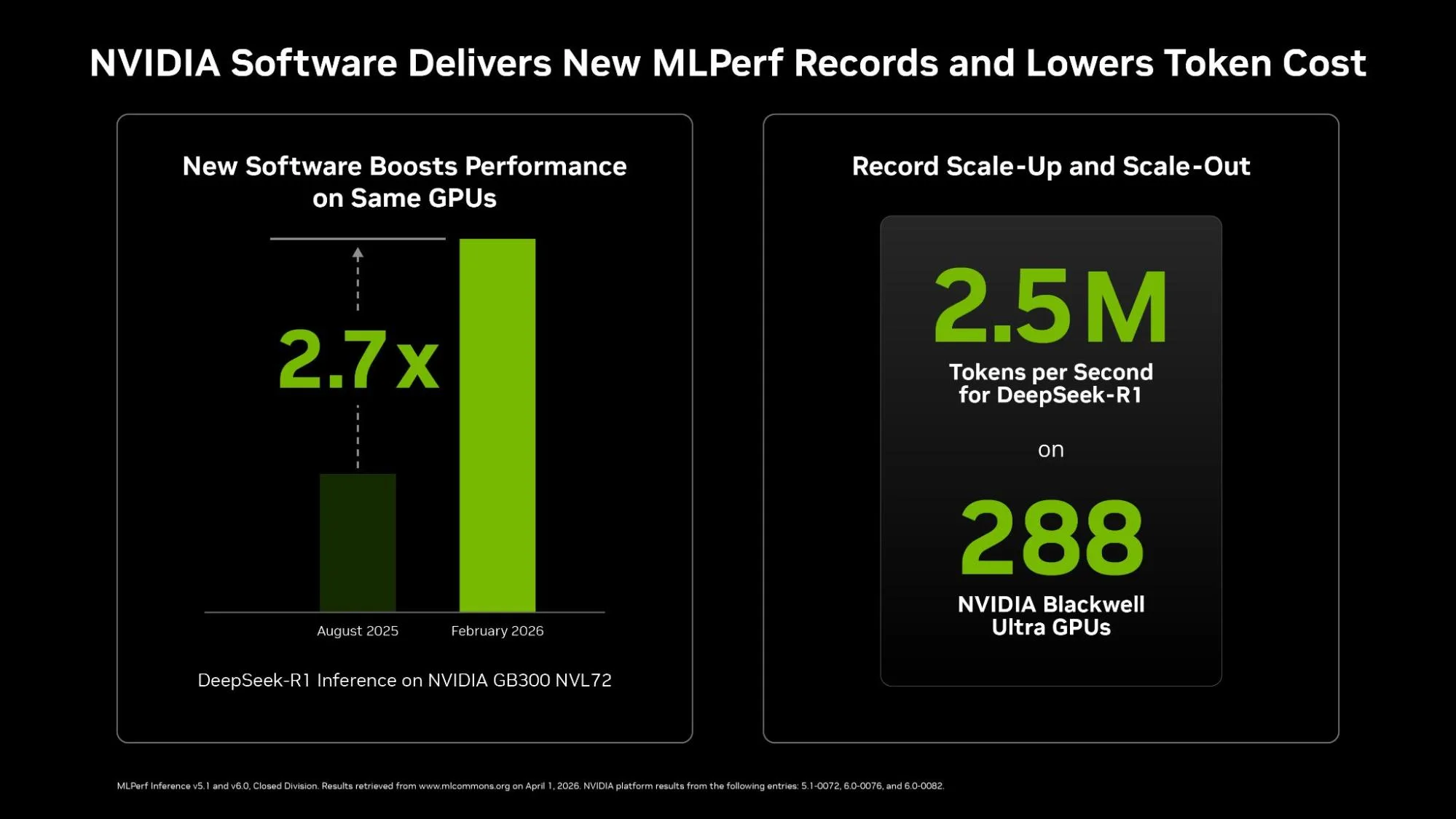
The most important part of NVIDIA’s message is not just that Blackwell Ultra posted fast numbers, but that the company is showing major gains on the same GB300 NVL72 platform without changing the hardware. In the official NVIDIA data, DeepSeek R1 server throughput on GB300 NVL72 increased from 2,907 tokens per second per GPU in v5.1 to 8,064 in v6.0, which is a 2.77x jump. DeepSeek R1 offline throughput rose from 5,842 to 9,821 tokens per second per GPU, while Llama 3.1 405B also saw gains in both server and offline scenarios. NVIDIA attributes this to what it calls extreme co design, meaning coordinated optimization across chips, systems, networking, software, and data center infrastructure rather than a simple raw silicon upgrade.
Here is the comparison NVIDIA published for GB300 NVL72 between MLPerf v5.1 and v6.0:
| Benchmark | GB300 NVL72 v5.1 | GB300 NVL72 v6.0 | Speedup |
|---|---|---|---|
| DeepSeek-R1 (Server) | 2,907 tokens/sec/gpu | 8,064 tokens/sec/gpu | 2.77x |
| DeepSeek-R1 (Offline) | 5,842 tokens/sec/gpu | 9,821 tokens/sec/gpu | 1.68x |
| Llama 3.1 405B (Server) | 170 tokens/sec/gpu | 259 tokens/sec/gpu | 1.52x |
| Llama 3.1 405B (Offline) | 224 tokens/sec/gpu | 271 tokens/sec/gpu | 1.21x |
That is where NVIDIA’s argument becomes strategically interesting. The company is not only selling Blackwell Ultra as faster hardware, it is selling a platform whose value continues to improve after deployment through ongoing optimization. For hyperscalers and enterprise AI buyers, that matters as much as launch day benchmark numbers, because the economics of large scale inference are tied directly to token throughput, system utilization, and power efficiency over time. NVIDIA is effectively telling customers that the platform they buy today can still become materially better through deeper tuning and integration work.
MLPerf v6.0 itself also helps NVIDIA make that case because the benchmark suite is becoming more demanding and more relevant. MLCommons says the new version expands open weight LLM coverage with GPT OSS 120B, introduces a new interactive DeepSeek R1 workload with strict low latency constraints, and continues to measure performance under formal accuracy and compliance requirements. That gives more weight to these results than a vendor controlled internal benchmark, even if NVIDIA is still naturally presenting the data in the most favorable way possible.
At the same time, it is important to separate what is benchmark structure and what is vendor interpretation. NVIDIA says its submission lead is 9 times greater than the nearest competitor in terms of inference wins, but the broader takeaway is less about a single headline and more about participation and consistency. NVIDIA remains one of the most active companies in MLPerf, regularly submitting across many categories and product generations, which gives it a very visible benchmarking presence. MLCommons publishes the results through its own datacenter results system, where vendors can compare across workloads, scenarios, and system types.
What this really signals is that NVIDIA is still widening its moat through a combination of hardware cadence and software maturity. Blackwell Ultra is clearly important, but the larger story is how much of the gain is being framed as platform level progress rather than only architectural progress. In an AI market where customers increasingly care about deployment cost, inference scale, and rack level economics, that is exactly the message NVIDIA wants MLPerf to reinforce. Based on the latest v6.0 round, it is a message the company is still delivering very effectively.
What do you think, is NVIDIA’s biggest advantage now the chip itself, or the software and system co design stack wrapped around it?